
Introduction
Recently, I implemented the Product Category Classification system using Semantic Kernel integrated with the Gemini Model. This system categorizes products into classes such as “Baby Products,” “Baby,” “Home and Tools Improvement,” and more based on their textual descriptions. The dataset used in this system is available on Kaggle and consists of data for over 42,000 products, including fields such as “ImgID,” “Product Title,” “Product Description,” and “Category.” Additionally, it includes product images, which are not required for our system. Before moving on to Retrieval Augmented Generation (RAG), let’s first review how the prompts work within the system.
What is Semantic Kernel?
Semantic Kernel is a lightweight, open-source development kit that lets you easily build AI agents and integrate the latest AI models into your C#, Python, or Java codebase. It serves as an efficient middleware that enables rapid delivery of enterprise-grade solutions. Ref
Working
The Product Category Classification system categorizes products based on their descriptions. Thanks to Semantic Kernel, which enables the integration of multiple ChatCompletion models within a single kernel. The diagram below provides a brief overview of how the system works. This system is built as a .NET Core MVC web application using Semantic Kernel.
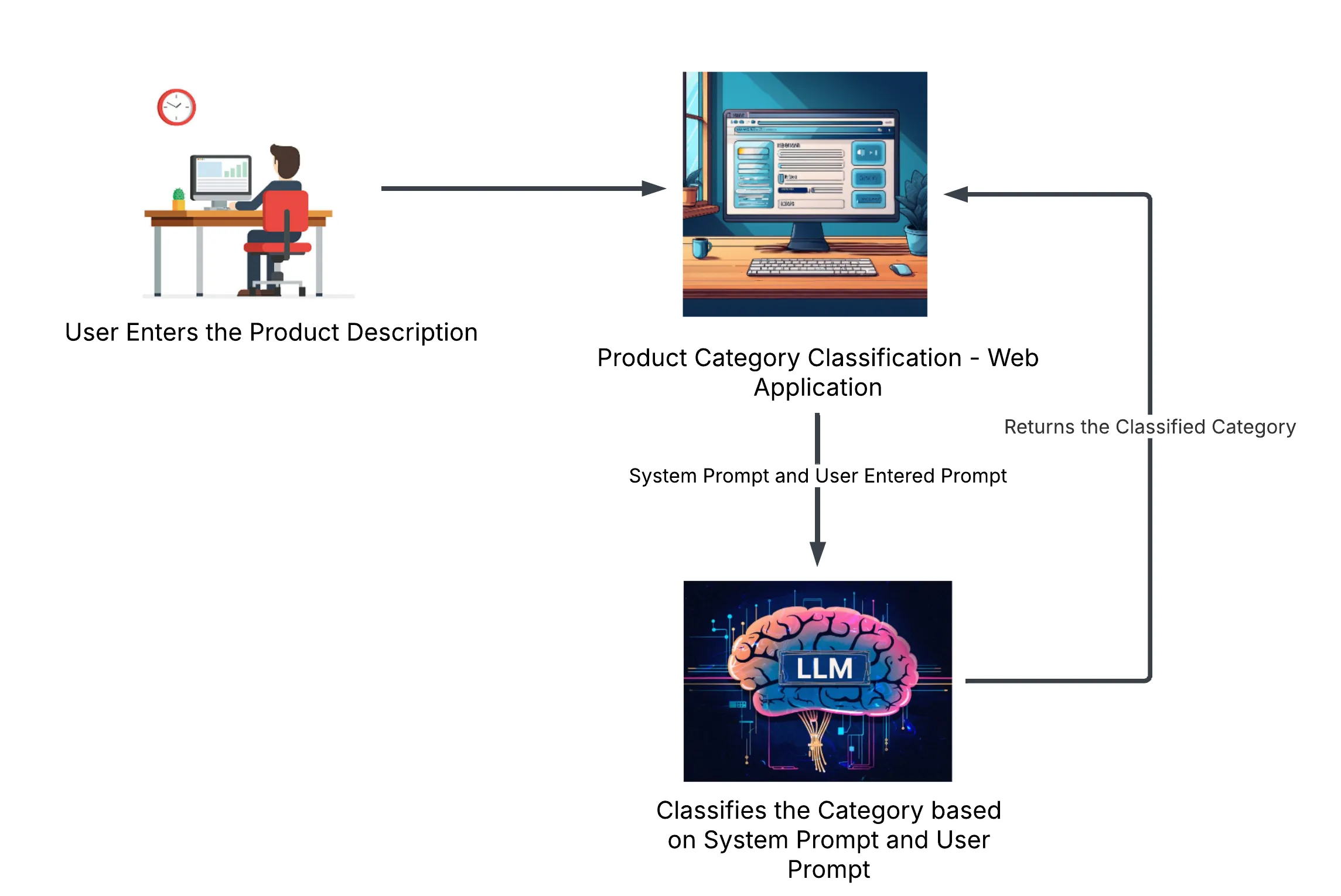
Issues in the Prompt
What is Prompt in AI?
In AI, a prompt is the input you provide to an AI model to get a specific response.
As we know, creating an AI application or system for a specific task requires integrating LLM models such as OpenAI, Gemini, or DeepSeek, along with effective prompts that work seamlessly with these models. In our case, we have provided a simple prompt that classifies the category:
Prompt:
<message role="system">
You are a classification bot responsible for categorizing a given description based on a predefined category list.
Category List:
["Arts", "Crafts", "Cell Phone", "Clothing", "Tools & Home", "Health & Personal", "Baby Products", "Patio", "Lawn & Garden", "Beauty & Cosmetics", "Electronics", "All Electronics", "Automotive", "Toys & Games", "All Beauty", "Office Products", "Appliances", "Musical Instruments", "Industrial", "Grocery & Food", "Pet Supplies", "Unknown"]
Classification Rules:
- Analyze the given description and assign the most appropriate category from the list.
- If the description lacks sufficient information to determine a category, classify it as "Limited Description".
- If no suitable category can be determined, classify it as "Unknown".
- Output only the category name, without any additional text or formatting eg:(All Electronics).
</message>
<message role="user">
**Description**: {{$description_provided_by_user}}
</message>The prompt above is used to classify the category from the 21 categories present in the dataset. This prompt does not know which product description will be provided, nor does it have any knowledge about the dataset we are using.
Let’s check the output for some product descriptions from the dataset. Below are two samples we are going to examine:
| Sample No | Description | Expected Category |
|---|---|---|
| 1 | Specifications: Cable Types: EIA/T1A T568A, EIA/TIA T5S8B, (AT&T258A;), USOC 4 Pair, Token-Ring, WBASE-T, TP-PMD and any RJ-45 cable. Battery: 9 V Alkaline, NED A 1604 A, such as Eveready 522 or DurMcell MN1604. Battery Life; Approximately 120 hours of testing. Approximately 6 months idle (No cable attached). Size: 3.7 L x 2.4 W x 1.1 H inches. Weight: Less than 7 oz. with battery installed | Industrial & Scientific |
| 2 | Vivitar’s Series1 19-35mm AF zoom lens for is designed to work with Canon autofocus single-lens reflex cameras. This lens is compact and lightweight, with an aperture range of f/3.5 to f/4.5 and a minimum focusing distance of 1.6 feet. Its macro ratio is 1:12x at 35mm and it takes 77mm accessories. | Electronics |
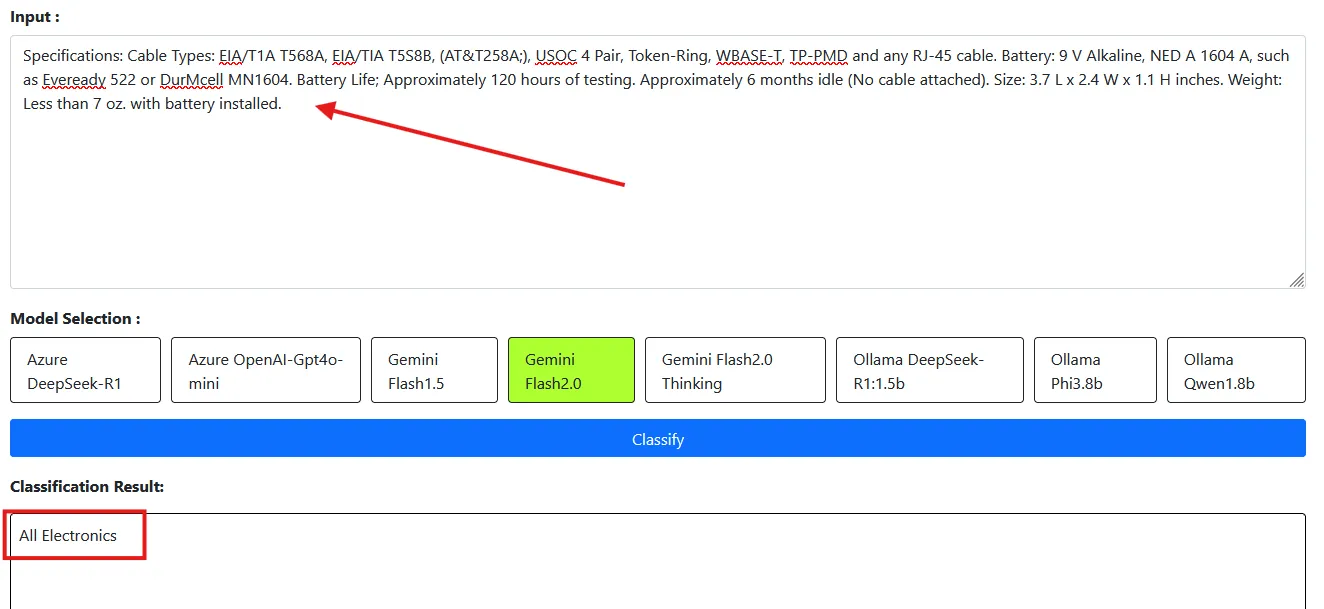
As you can see, in Sample 1 the result is “All Electronics” instead of “Industrial & Scientific.” The dataset assigns the category as “Industrial and Scientific,” but the LLM model does not have knowledge of the dataset. We want the category to be classified based on the dataset. Although the model context provides the correct category, it is not aligned with the dataset.
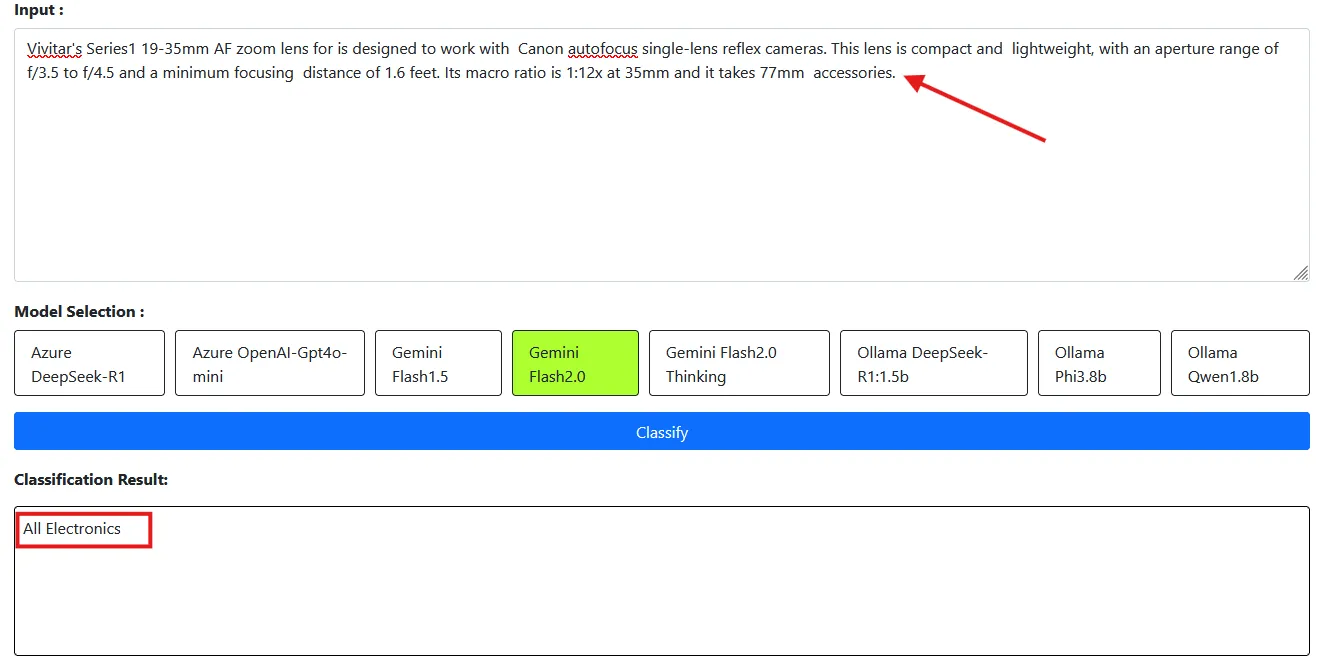
For Sample 2, we expected the category to be “Electronics,” but the model returned “All Electronics.”
Why Did These Classification Problems Occur?
These classification issues occur because our prompt only instructs the model to pick a category from a list, without explaining the subtle differences between similar categories. For example, the dataset includes both “Electronics” and “All Electronics,” as well as “Baby” and “Baby Products,” and “Beauty” and “All Beauty.” Since the model is trained on a wide range of data, it doesn’t know the specific rules or nuances of our dataset. As a result, even though the model classifies correctly in a general sense, it sometimes chooses a category that doesn’t match the exact definitions provided by the dataset.
Improving the Prompt
Let’s try to solve the problem by providing some context about the categories present in the dataset within the system prompt.
Prompt:
You are the Product Category Classifier Assistant. Your task is to classify a product into the most specific category based on its description.
***Category List:***
["Arts, Crafts & Sewing"| "Cell Phones & Accessories"| "Clothing, Shoes & Jewelry"| "Tools & Home Improvement"|"Health & Personal Care"| "Baby Products"| "Baby"| "Patio, Lawn & Garden"| "Beauty"Sports & Outdoors"| "Electronics"| "All Electronics"| "Automotive"| "Toys & Games"| "All Beauty| "Office Products"| "Appliances"| "Musical Instruments"| "Industrial & Scientific"|"Grocery & Gourmet Food"| "Pet Supplies"| "Unknown"]
[[Classification Rules]]
- Analyze the Provided **Description** Carefully then classify its category from the **Category List**.
- Do not select categories outside the Category list.
- If no category fits, say "Unknown".
[Category Definitions]]
"Electronics" - Consumer electronic devices such as headphones, cameras, televisions, smartwatches, speakers.
"All Electronics" - Broader electronics category covering components, accessories, chargers, boards, kids electronics gadget, cables, and general tech items that don’t fit under "Electronics".
"Beauty": Everyday beauty and personal care items.
"All Beauty": Comprehensive range including professional, specialized, fragrance related items, facial spray, products used to store multiple beauty products, and niche beauty products.
"Health & Personal Care" - Medical, hygiene, or health-related products including first-aid supplies supplements, dental care, over-the-counter medicine, and personal hygiene items.
"Baby" - Essential baby care products such as diapers, formula, baby wipes, and feeding bottles.
"Baby Products" - Non-essential baby items such as toys, storage for toys, rattles, baby clothing, or baby accessories.
"Industrial & Scientific" - Tools, Material Which are used in Industries but are not related to "Automotive", "Tools & Home Improvement".
"Tools & Home Improvement" – Hand tools, power tools, and home improvement products such as nylon tools and construction materials.
Give only category as the output
[[Example]]
**Baby Products**In the above prompt, we provided definitions for the categories that were causing classification issues. Let’s check the samples to see if it can now correctly classify:
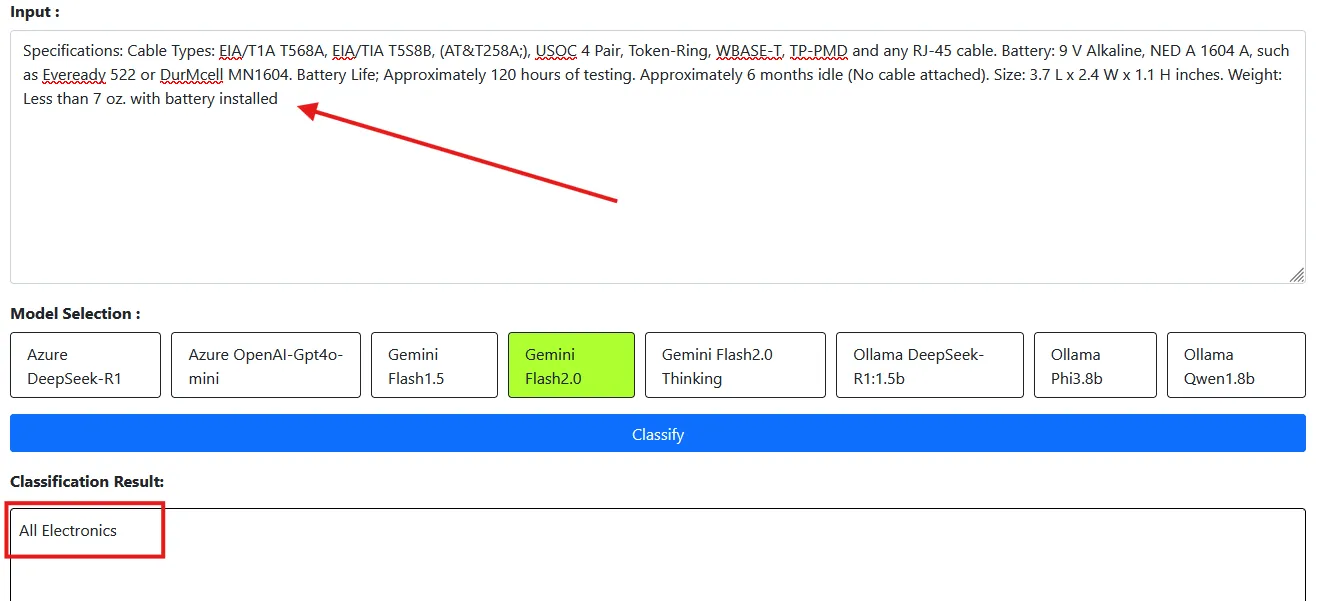
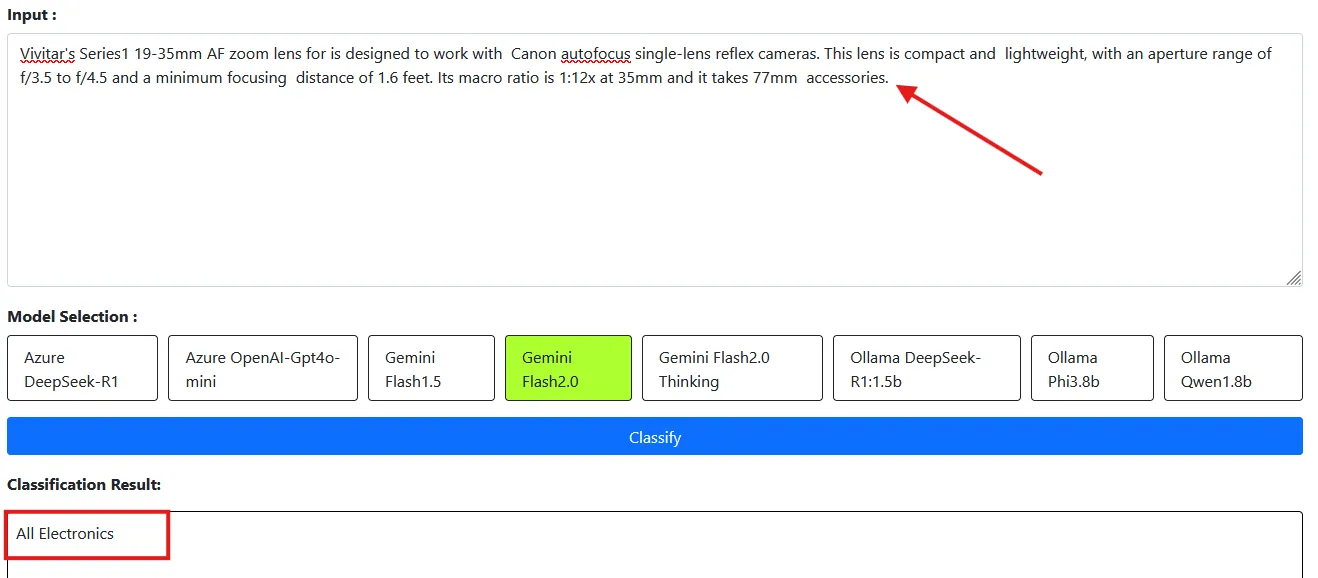
Even with explicit differences outlined in the prompt, the LLM model still misclassifies some categories. This is because the dataset is broad, with subtle distinctions between similar categories like “Electronics” versus “All Electronics” and “Baby” versus “Baby Products.” However, while the system has improved for some descriptions, it still struggles with categories that appear similar.
How to tackle These Problem?
Below are some approaches to solve the classification problem:
- Refine the Prompt: We can include examples in the prompt, but since the dataset is vast and contains many descriptions, adding too many examples would make the prompt lengthy and ineffective.
- Fine-Tuning: Fine-tuning the model on our dataset allows it to learn from our specific data, but this approach is both costly and time-consuming.
- Retrieval-Augmented Generation (RAG): This is the most promising approach. By providing relevant examples through tool calls, it is cost-effective, though it may still require some time.
- Training From Scratch: This approach offers full control and precise customization for our task, but it still requires significant expertise and regular updates—especially if new categories emerge, which might necessitate retraining the model.
Here comes Retrieval-Augmented Generation (RAG). We will see how RAG solves our problem in our Next Blog.