
Building a Recommendation System Using Text Embeddings and python
Learn how to create a simple recommendation system for e-commerce using vector embeddings and Gradio.
Recommendation systems are tools that analyze user preferences and suggest items like products, movies, or music. They’re everywhere in our lives, from suggesting songs on Spotify to recommending products on Amazon and even recommending friends on social media platforms like Facebook. These systems have a deep impact on our daily lives, influencing what we consume, how we shop, and even who we interact with online.
In this blog, we’ll walk through the process of building a straightforward yet effective recommendation system using Vector embeddings and Gradio.
Vector embeddings
Vector Embeddings are numerical representations of data that capture semantic information. This data can be text, images, audio, structured, or unstructured. The approach revolves around converting product descriptions into vectors in a high-dimensional space. This allows products with similar attributes to be placed closer together. For instance, when a user queries “Casual black leather jacket,” its embedding will be compared against the product catalog to find the most relevant items.
Prerequisites
Ensure you have the following installed before starting:
- Python 3.12.x
- Visual Studio Code or any IDE of your choice
Step 1: Setting Up the Environment
To begin, set up a project directory and virtual environment. For Windows users:
- Create a project folder and open it in VS Code:
mkdir recommendation_system
code recommendation_system - Install Python (if not already installed) and set up and activate a virtual environment:
python -m venv venv
.\venv\Scripts\activate
# for Powershell
# .\venv\Scripts\Activate.ps1- Install the required libraries:
pip install sentence-transformers gradioHere we are using the sentence-transformers library for generating embeddings and the gradio library for creating a user interface.
Step 2: Preparing the Data
I am using the Fasion product images dataset, which I have combined into a single ecommerce_data.csv file. The file has the following columns:
- gender: Target audience (e.g., “Men” or “Women”).
- masterCategory: General product category (e.g., “Apparel”).
- subCategory: Specific type (e.g., “T-Shirts”).
- articleType: Description of the item (e.g., “Casual T-shirt”).
- baseColour: Primary color.
- season: Relevant season (e.g., “Winter”).
- year: Launch year.
- usage: Use case (e.g., “Casual,” “Formal”).
- productDisplayName: Full name. -link: Product image link
To streamline the process, we’re merging all text fields except for link into a single string representation for generating one embedding per item:
import pandas as pd
# Load the data
data = pd.read_csv("ecommerce_data.csv")
data['combined_features'] = data.apply(
lambda row: f"{row['gender']} {row['masterCategory']} {row['subCategory']} {row['articleType']} {row['baseColour']} {row['season']} {row['year']} {row['usage']} {row['productDisplayName']}",
axis=1
)Step 3: Generating Embeddings
Model Selection
We’ll use the all-MiniLM-L6-v2 model from the Sentence-Transformers library. It’s an efficient text-only embedding model suitable for smaller datasets. We will convert the combined product metadata into vector embeddings and save them as a NumPy array file.
In production scenarios, this step would usually involve ETL (Extract, Transform, Load) pipelines to extract product metadata from the various sources, transform it into a suitable format, and load it into a vector database like Pinecone or Qdrant. This process would also involve storing the embeddings along with indexing and metadata (e.g., product ID, category, etc.) for efficient retrieval and filters.
# Load the model
from sentence_transformers import SentenceTransformer
import numpy as np
sentence_model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = sentence_model.encode(data['combined_features'].tolist())
np.save("ecommerce_embeddings.npy", embeddings) # Save embeddings for later useStep 4: Building the Recommendation System
Finding Similar Products
The system computes the cosine similarity between the user query’s embedding and all product embeddings to find the closest matches. The cosine similarity measures how close two vectors are in terms of their orientation in high-dimensional space. A cosine similarity of 1 means the vectors are identical, while a cosine similarity of -1 means they are opposite. The cosine similarity is a widely used metric for similarity search tasks. By filtering the results based on a similarity threshold, we can control the quality of the results.
from sklearn.metrics.pairwise import cosine_similarity
def vector_search(query, embeddings, data, top_n=5, similarity_threshold=0.4):
query_embedding = sentence_model.encode(query)
similarities = cosine_similarity([query_embedding], embeddings)[0]
valid_indices = np.where(similarities >= similarity_threshold)[0]
sorted_indices = valid_indices[similarities[valid_indices].argsort()[::-1]]
return data.iloc[sorted_indices[:top_n]]Custom Filters
You can refine results by applying filters:
results = vector_search(
query="Casual black leather jacket for winter",
embeddings=embeddings,
data=data,
top_n=5,
similarity_threshold=0.5
)Step 5: Deploying with Gradio
Finally, we are using Gradio to create a web interface for our recommendation system:
import gradio as gr
def get_recommendations(query):
results = vector_search(query, embeddings, data)
return results[['productDisplayName', 'masterCategory', 'subCategory', 'baseColour']].to_html(index=False)
gr.Interface(
flagging_mode='never',
fn=get_recommendations,
inputs=gr.Textbox(label="Describe Your Fashion Preferences"),
outputs=gr.HTML(label="Recommendations"),
title="Fashion Recommendation System"
).launch()Below is the complete code in an app.py file.
import gradio as gr
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
import numpy as np
import pandas as pd
# Load the model
sentence_model = SentenceTransformer("all-MiniLM-L6-v2")
# Load the data
data = pd.read_csv("ecommerce_data.csv")
# Concatenate the text features into a single string for each product
data['combined_features'] = data.apply(lambda row: f"{row['gender']} {row['masterCategory']} {row['subCategory']} {row['articleType']} {row['baseColour']} {row['season']} {row['year']} {row['usage']} {row['productDisplayName']} ", axis=1)
# Generate embeddings
embeddings = sentence_model.encode(data['combined_features'].tolist())
# Save the embeddings
np.save("ecommerce_embeddings.npy", embeddings)
embeddings = np.load("ecommerce_embeddings.npy")
def vector_search(query, embeddings, data, top_n=5, similarity_threshold=0.4):
query_embedding = sentence_model.encode(query)
similarities = cosine_similarity([query_embedding], embeddings)[0]
valid_indices = np.where(similarities >= similarity_threshold)[0]
sorted_indices = valid_indices[similarities[valid_indices].argsort()[::-1]]
return data.iloc[sorted_indices[:top_n]]
def get_recommendations(query):
results = vector_search(query, embeddings, data)
return results[['productDisplayName', 'masterCategory', 'subCategory', 'baseColour']].to_html(index=False)
gr.Interface(
flagging_mode='never',
fn=get_recommendations,
inputs=gr.Textbox(label="Describe Your Fashion Preferences"),
outputs=gr.HTML(label="Recommendations"),
title="Fashion Recommendation System"
).launch()You can run it by the following command (make sure the virtual environment is activated):
python app.py 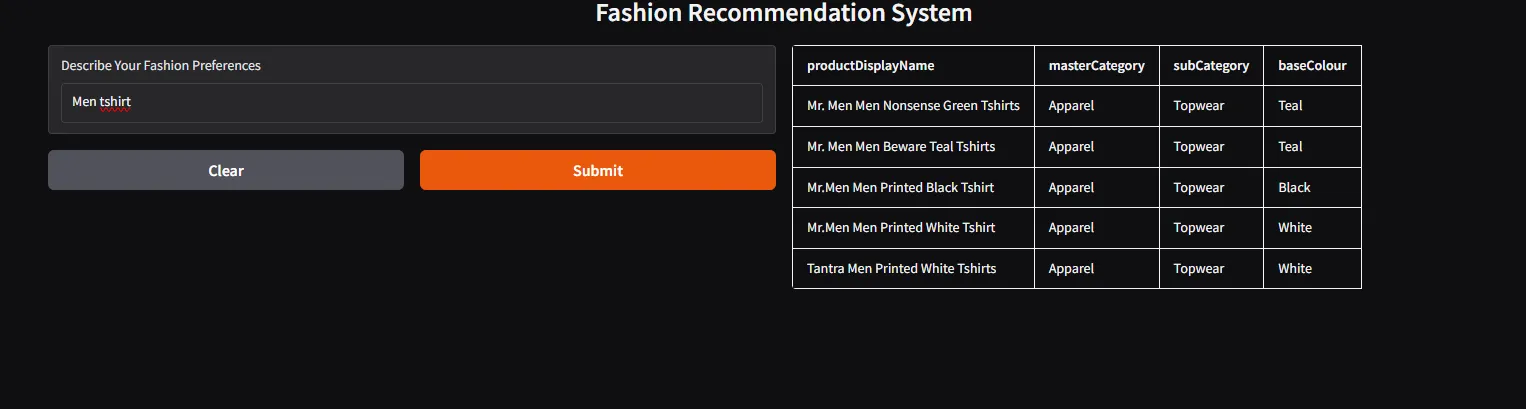
Check our live demo app along with the source code here. It’s a modified version of the above code with better UI while keeping the core functionality the same.
Wrapping Up
In this blog, we’ve built a simple yet effective recommendation system using vector embeddings and Gradio. The Gradio library provided an easy-to-use interface, making it simple to deploy our recommendation system as a web application.
Overall, this project demonstrates how embeddings can be utilized effectively in recommendation systems without the need to train the models from scratch. Ofcourse this won’t give the best results compared to the state-of-the-art recommendation systems, but it can serve as a good starting point.