
Should you use GPT-4o-mini for multimodal tasks?
A deep dive into the real costs and limitations of gpt-4o-mini for image processing tasks.
When OpenAI introduced GPT-4o-mini as a more cost-effective alternative to GPT-4o, it seemed like an obvious choice for to switch. The potential for reducing expenses while maintaining robust performance was enticing—at least on paper.
However, during the migration of our multimodal application to GPT-4o-mini on Azure, I encountered something surprising: despite using minimal input—just a simple text prompt and a single image—the requests were consuming nearly 50,000 tokens. Even more baffling, these requests were breaking through our 20,000 token deployment limit despite being well within the expected resource usage.
Was this a bug or a feature? Let me take you through what I discovered.
Investigating the root cause
To diagnose the problem, I created a minimal reproduction of the issue. Here’s what I set up using .NET and Semantic kernel:
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.ChatCompletion;
//Build the kernel
Kernel kernel = Kernel.CreateBuilder()
.AddAzureOpenAIChatCompletion(
"gpt-4o-mini",
"<ENDPOINT>",
"<APIKEY>"
)
.Build();
//Get the chat completion service
IChatCompletionService chatCompletionService = kernel.GetRequiredService<IChatCompletionService>();
//Build the chat history
ChatHistory chatHistory = new();
chatHistory.AddUserMessage(new ChatMessageContentItemCollection()
{
new TextContent("Describe this image"),
new ImageContent(new Uri("https://example.com/image.png"))
});
//Make the request
var content = await chatCompletionService.GetChatMessageContentAsync(chatHistory);
Console.WriteLine(content);This was an intentionally simple console app: it sends a text prompt (“Describe this image”) and an accompanying image URL to the GPT-4o-mini model. The expectation was that the resource usage would be minimal due to the simplicity of the request.
However, when I examined the response metadata, it revealed something unexpected: the token count was significantly inflated, mostly due to how images were processed. Below is an example of the metadata, showcasing how token usage spiraled beyond the expected limits:

Not All Cost Savings Are Created Equal
At first glance, GPT-4o-mini seems like a no-brainer for organizations looking to cut costs. Its marketing emphasizes reduced expenses for text processing, which can make a significant difference for text-heavy applications. However, the situation becomes more complicated when multimodal tasks, such as those involving images, enter the equation.
The core issue lies in how GPT-4o-mini handles tokens. While its pricing is indeed lower for text inputs (33x cheaper), the image processing retains the same underlying cost structure as GPT-4o. This means that any perceived cost savings are only applicable to the text portion of your requests. For tasks involving images, the same amount of processing power and resources are used, leading to identical token costs as GPT-4o.
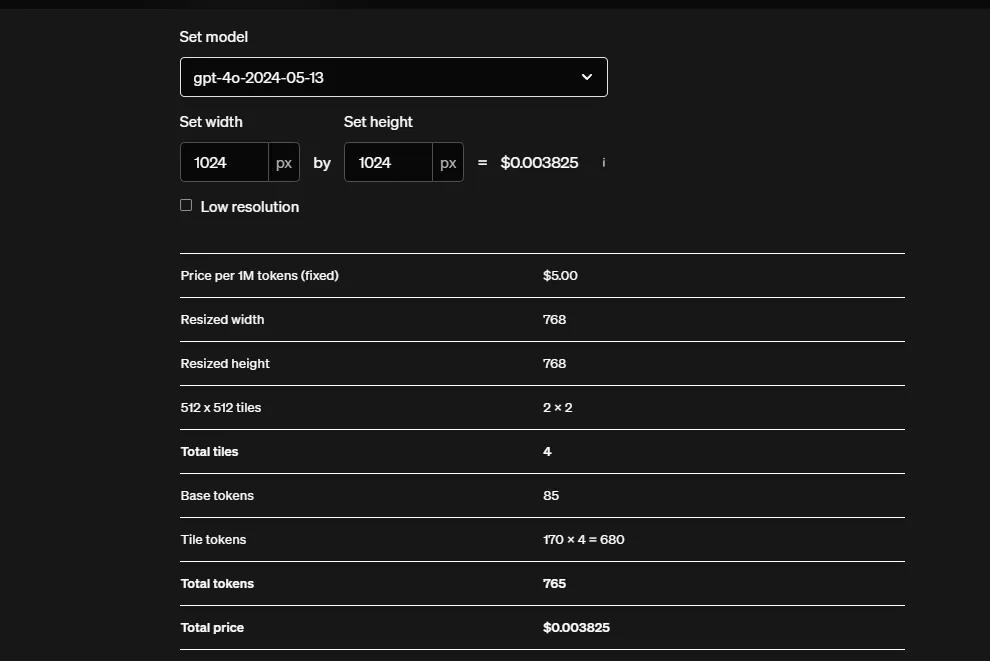
Here are the token usage and pricing for both GPT-4o and GPT-4o-mini from the OpenAI’s pricing page:
GPT-4o Pricings:
GPT-4o-mini Pricings:
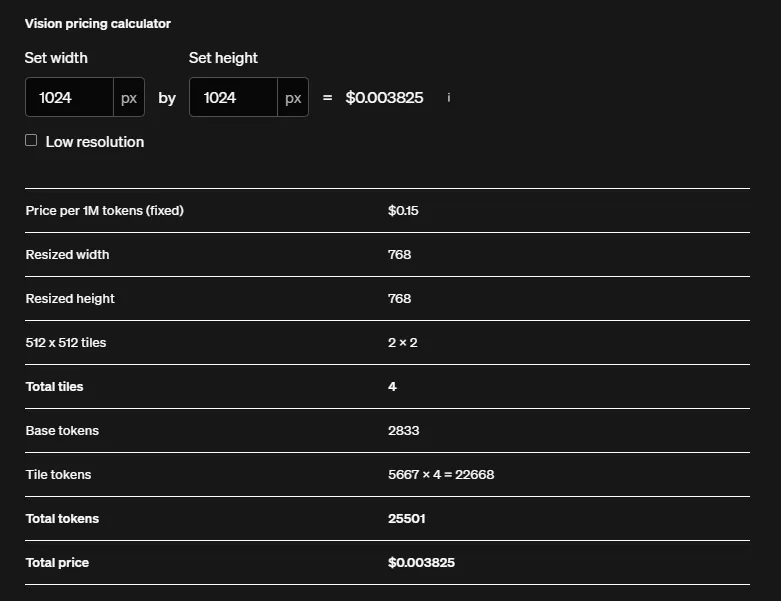
Notice that their an x33 increase in the token usage for GPT-4o-mini and the pricing is the same as GPT-4o. That explains the sudden increase in token usage, but what about my rate limits set on Azure? Why weren’t they being applied?
After further testing with the GPT-4o-mini models, I reached a conclusion: Azure does not seem to enforce rate limits for GPT-4o-mini when processing images, at least not according to the metrics displayed.
When using the GPT-4o-mini models there are two separate token usage to keep track of
-
The Resource tokens: These represent the actual workload on the model. For example, processing an image uses the same number of resource tokens on both GPT-4o and GPT-4o-mini. Resource tokens are what Azure uses to enforce rate limits and define system throughput.
-
The Billing tokens: These are used to calculate the monetary cost of each request. Unlike resource tokens, GPT-4o-mini applies a multiplier (e.g., 33x for images) to determine billing tokens. Billing tokens are displayed in Azure’s metrics and API responses, but they have no impact on rate limits.
The result is a paradoxical situation: while GPT-4o-mini may appear cheaper for text-heavy workloads, the inflated billing token multiplier for image tasks makes it potentially more expensive and significantly harder to manage.
What This Means in Practice
Let’s consider a hypothetical application that processes high-resolution images:
Scenario:
- You set a 1,000-token rate limit per request.
- Each request includes a single image.
Using GPT-4o:
- The model uses 1,000 resource tokens for processing.
- You’re charged for 1,000 billing tokens at GPT-4o’s standard rate.
Using GPT-4o-mini:
- The model still uses 1,000 resource tokens (same as GPT-4o).
- However, due to the 33x multiplier, you’re charged for 33,000 billing tokens.
This creates a misalignment: while both models have the same throughput limits, GPT-4o-mini inflates token usage without offering any additional processing capacity for keeping the billing consistant.
Now if are rate-limiting your end-users based on their token usage you, switching models could reduce your throughput by 33x, even though their actual usage and pricing haven’t changed at all.
Final Thoughts
Choosing the right AI model is never as simple as comparing price tags. While GPT-4o-mini offers exciting potential for cost reduction, its behavior in production reveals hidden costs and challenges that can undermine those savings.
If your workload is primarily text-based, GPT-4o-mini might be a great fit. But if images or other multimodal elements play a significant role, tread carefully. Understanding these nuances can save you from unexpected costs and operational headaches.