
Function calling using Semantic Kernel
Using the gpt-4 function calling capabilities with semantic kernel
Introduction
With the rapid adoption of AI technologies in our day-to-day lives, the way we interact with digital systems is changing continuously.
Traditional machine learning models weren’t flexible eno ugh and were generally limited to being specialized in one task. But this trend shifted with the introduction of Large language models. Due to the vast general capabilities and skills present in these Language models they could be used as general-purpose models excelling in various language tasks.
Further, we can finetune these models to match our use case, making them better at one task without affecting their existing capabilities too much. The functional calling capabilities of gpt-4 are the result of one such fine-tuning method.
In this blog, we will talk more about the function calling capabilities of gpt-4 and how it integrates with Semantic Kernel.
Function Calling in OpenAI models
So how exactly does the function calling work in gpt-4?
Whenever the gpt-4 model receives a prompt, we can also pass in the functions as a json schema that describes what the function does in natural language. The model doesn’t call the function but rather replies with a function signature with available parameters for completing the required task.
For example, if we ask a model what the current time is, we won’t get the desired answer.
User: what time is it?
Assistant: I am sorry, but as a Large Language Model I don't have access to current time information.We could fix this by providing the model a get time function that always returns the current time when called.
Below is a sample json scheme that describes our function to our AI assistant
{
"name": "getCurrentTime",
"description": "Get the current time",
"parameters": {}
}Now when we ask the assistant what time is it? it will
System Message :
AVAILABLE FUNCTIONS-
1. getCurrentTime // Json schema for the function
User: what time is it?
//Internal
Tool call: Function(getCurrentTime)
Tool call response : 10:00:00
Assistant : The current time is 10:00:00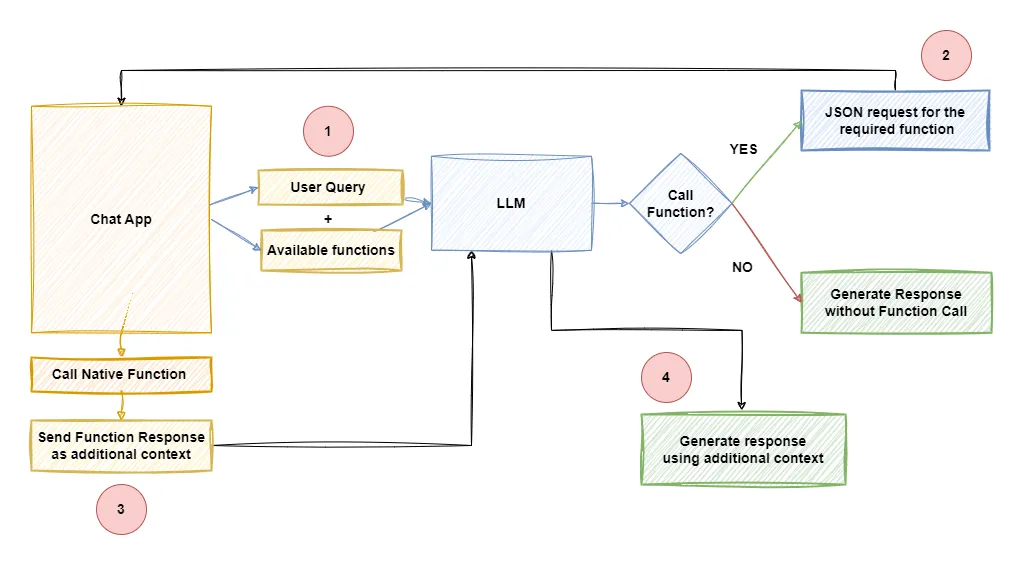
The sequence of steps for function calling is as follows:
- The user sends a message along with a set of functions defined in the functions parameter.
- The model can choose to call one or more functions if required.
- The application executes the function and sends the function output to the LLM
- The LLM uses this function output as additional context to generate a response
So internally we call the model at least twice before displaying a response to the user when using function calling.
Using Function Calling with Semantic Kernel
Now that we have an idea of how function calling works, let’s implement using the Semantic kernel SDK.
Let’s first define our function
private static string GetCurrentTime()
{
return DateTime.UtcNow.ToString();
}Next, let’s set our kernel and add the function as a plugin in our kernel
//Add OpenAI service and build the kernel
IKernelBuilder builder = Kernel.CreateBuilder();
builder.AddOpenAIChatCompletion("<Model-Name>", "<API-Key>");
Kernel kernel = builder.Build();
//Add the current time function as a plugin
kernel.ImportPluginFromFunctions("TimePlugin", new[] {
kernel.CreateFunctionFromMethod(GetCurrentTime, "GetCurrentTime", "Retrieves the current time in UTC.")
});Here’s the question we will be asking the LLM.
string prompt = "What time it is?";First, let’s try to call the LLM without function calling enabled
var result = await kernel.InvokePromptAsync(prompt);
Console.WriteLine(result);Output
"I'm sorry, I don't have access to real-time information, so I can't tell you the current time. Please check a clock or your device for the current time."This response is expected since the model doesn’t have access to real-time data
Semantic kernel gives us multiple options about how we want to handle the function call
- Either we can handle it manually by using
ToolCallBehavior = ToolCallBehavior.EnableKernelFunctions - Else we can let semantic kernel handle it internally by using
ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions
ToolCallBehavior.AutoInvokeKernelFunctions handles the function calling internally without having to explicitly add code to handle it.
This allows us to quickly use function calling in our application without too much effort. It’s also great for simple use cases where the model can reliably call the functions. But due to the inherently unpredictable nature of the LLM models, this may not work for every scenario. For more controlled flow ToolCallBehavior = ToolCallBehavior.EnableKernelFunctions is recommended.
To enable the auto tool call behavior we need to pass the execution settings while invoking a prompt
OpenAIPromptExecutionSettings settings = new OpenAIPromptExecutionSettings()
{ToolCallBehavior = ToolCallBehavior.AutoInvokeKernelFunctions };
var result = await kernel.InvokePromptAsync(prompt, new KernelArguments(settings));
Console.WriteLine(result);
When successful we should get the current time as an output.
The current time is 03:55:06 UTC on March 18, 2024.Here’s a look at what happens internally
//1st LLM call
Rendered prompt: What time it is?
Prompt tokens: 54. Completion tokens: 13. Total tokens: 67.
// Auto function calling enabled
Tool requests: 1
Function call requests: TimePlugin-GetCurrentTime({})
Function GetCurrentTime invoking.
Function arguments: {}
Function GetCurrentTime succeeded.
Function result: 18-03-2024 03:55:06
//2nd LLM call
Prompt tokens: 90. Completion tokens: 21. Total tokens: 111.
//Final response
The current time is 03:55:06 UTC on March 18, 2024.The auto function calling handles the application side of the function checking for any function call request from the LLM along with executing them and sending the response back to the LLM service.
So with function calling we are sending the same prompt twice with additional context added during the second invocation.
Wrapping Up
While the implementation of function calling with Semantic Kernel SDK has further simplified the process, making it more accessible for developers, it’s important to note that while the auto function calling feature is convenient, it may not be suitable for all scenarios due to the inherent unpredictability of large language models.
In the upcoming blog, we will be using the function calling with manual mode.