
Quick Setup for a local embedding Server using python
Setting up a local embedding service using Python for development
 Yash Worlikar Mon Feb 26 2024 3 min read
Yash Worlikar Mon Feb 26 2024 3 min read Embedding in your AI-powered applications
Embeddings play a crucial role in bridging the gap between your data and AI models. They transform complex data (text, images, audio, etc.) into low-dimensional numerical representations that computers can readily understand and process.
Unlike your LLM models, embeddings are unique in a way that once chosen, you are locked in for that vendor. While you can easily experiment different LLM models without breaking your application this isn’t the case for embedding models.
Any query made against the embeddings must also be made using the same embedding model. If you ever choose to change your existing embedding model, the existing embeddings become useless and the entire database must embedded again.
Using different models one for embedding data and one for querying is like using google search with devanagari while trying to find an Germen website. Any such queries will result in nonsensical results.
Not to mention experimenting with large datasets will quickly add up costs without much benefit compared to a local model. While the proprietary embeddings come with their benefits, in a local environment open source or custom embedding models are preferable.
Implementing a python backend server for local embeddings
Now that we have discussed why one might use a local or custom embedding model let’s implement one ourselves.
We will be creating a simple python project for our embedding service as a backend using fastapi and sentence transformers with Visual Studio Code as my IDE.
We will be using the all-MiniLM-L6-v2 model but we can choose any other available model on HuggingFace.
Prerequisites
- visual studio code (or any IDE of your choice)
- python
Note I am currently using a Windows PC, so some commands may differ for other OS
Let’s first create a directory named local-embedding-server and open it in vs code
mkdir local-embedding-server
code local-embedding-server & exit
Now open up the terminal in vs code and create and activate a virtual environment
python -m venv ./venv
.\venv\Scripts\Activate.ps1
Once the virtual environment is activated we can now install our required python packages. Make sure your virtual environment is active before running this command.
pip install fastapi sentence_transformers uvicorn
Here we are using the fastapi and unicorn to quickly spin up a RestAPI server and the
sentence_transformer to download an embedding model and
Now let’s create a main.py file and use the following code to create a backend server
from fastapi import FastAPI
from pydantic import BaseModel
from sentence_transformers import SentenceTransformer
class EmbeddingRequest(BaseModel):
Input: str
class EmbeddingResponse(BaseModel):
Data: list
model = SentenceTransformer("all-MiniLM-L6-v2")
#model = SentenceTransformer("<local path to your embedding model>")
app = FastAPI()
@app.post("/embedding", response_model=EmbeddingResponse)
async def create_embedding(embedding_request: EmbeddingRequest):
embedding = model.encode([embedding_request.Input])
response = EmbeddingResponse(Data=embedding.tolist())
return response
During the first run the sentence_transformer library will download the all-MiniLM-L6-v2 and store it locally. Alternatively, we can provide the path to our downloaded models if required.
This will be the embedding model that will be used for generating our embedding.
We are also exposing a single RestAPI endpoint named embedding for other applications to call to.
Now we can start our embedding server through the vs code terminal
uvicorn main:app --reload
We should be seeing the following message once the server is successfully started.

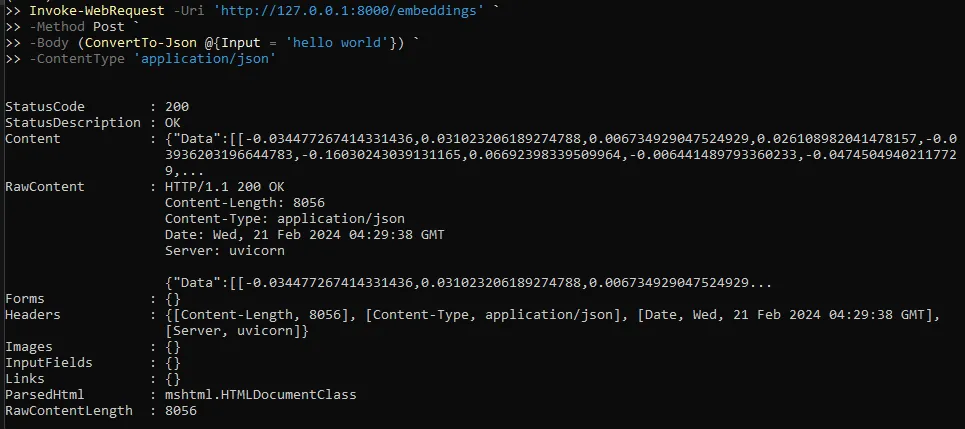
We can check if the API is working by sending a simple post call to http://127.0.0.1:8000/embedding
Invoke-WebRequest -Uri 'http://127.0.0.1:8000/embeddings' `
-Method Post `
-Body (ConvertTo-Json @{Input = 'hello world'}) `
-ContentType 'application/json'
Great once set up we can integrate this Rest API with our other applications to generate embeddings locally. In the future, we will be adding this as an embedding service in an AI-powered applications using Semantic kernel.