
Introduction
LLMs are powerful AI models that can understand structure and generate natural language using deep neural networks. LLMs are very good at performing various natural language tasks, such as translation, summarization, and question answering without being trained for a specific task.
The rise of AI-driven technologies has ushered in a new era of transformative applications. These AI-powered solutions are fundamentally altering various domains and may forever change how we live in the future.
However, as LLMs are still a relatively new technology their adoption comes with several limitations and challenges:
- They may not have access to the most current, reliable, or specific facts that are needed for some tasks
- They may generate inconsistent, inaccurate, or biased responses based on their training data
- They may not provide any sources or explanations for their responses, making them hard to trust or verify
Retrieval-augmented generation or RAG in short is a technique that aims to address some of these limitations by combining LLMs with a retrieval mechanism. The retrieval mechanism is a way of finding relevant information from a set of custom or proprietary documents and appending it into the prompt as additional context before sending it to the LLMs.
What is needed for Retrieval-Augmented Generation?
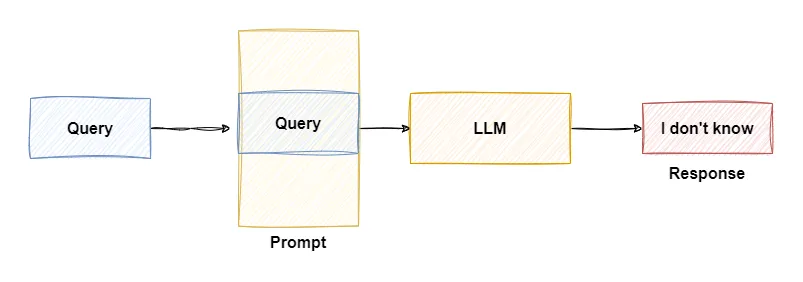
LLMs have a maximum input limit referred to as Context Length outside of which the model starts producing incoherent sentences. So we can’t just provide large documents to LLMs as additional context.
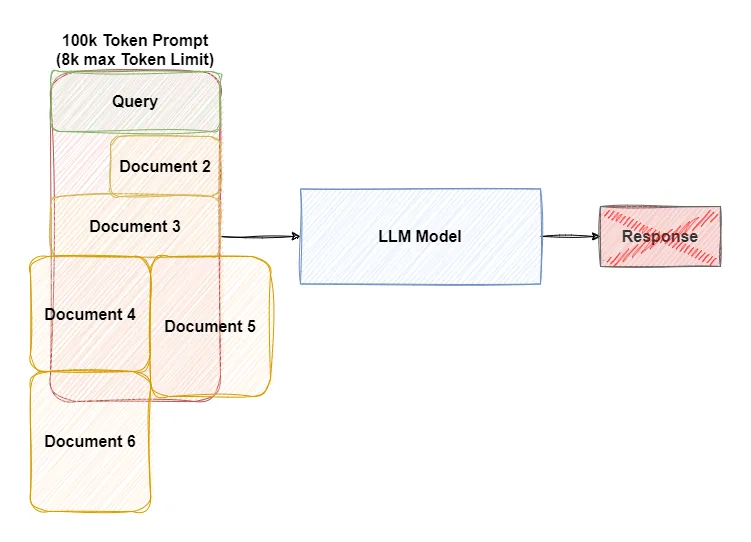
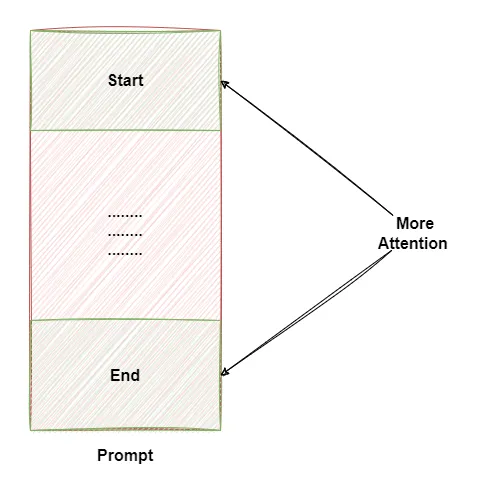
For larger context LLMs tend to focus more at the start and end of a prompt. This restriction can hinder their understanding of longer documents or broader contexts, leading to potential inaccuracies or incomplete responses.
Retrieval-augmented generation attempts to solve the context length limitations of LLMs by integrating a retrieval mechanism. This allows the model to have additional information beyond its pre-set context window by retrieving relevant data from a repository of documents or knowledge sources.
How does RAG work?
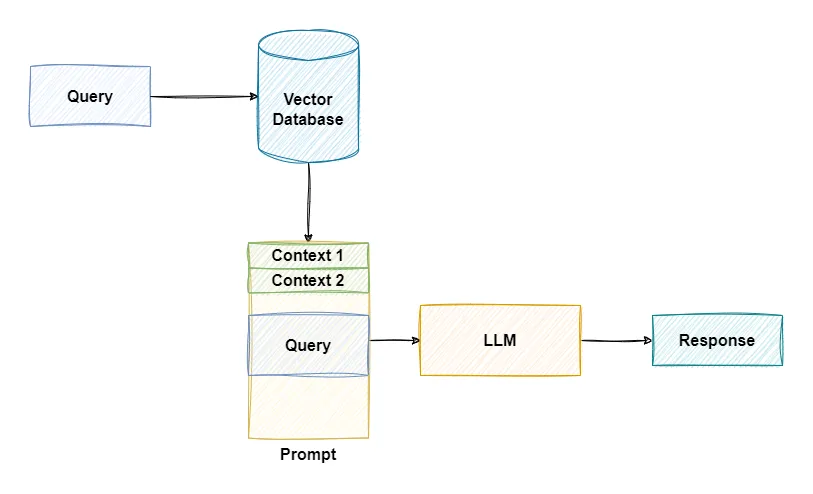
While the implementation of a RAG system may widely differ based on the use case. A simple RAG system may just involve an LLM service, a vector database and some linear code binding it together. Here’s a simple RAG workflow
-
Whenever a query is sent to the application the query is match against a vector database to get related documents.
-
The database contains embeddings that represents variety of data including books, images or even internal documents.
-
Through advanced search algorithm, the most relevant results are returned back.
-
The results are then injected into the prompt as additional context before being sent to the LLMs service.
-
With the help of this additional context the LLMs can answer question that previously weren’t possible
-
Without Context
<User>
### Question: What day is tomorrow?
<LLM Response>
### I don't have real-time access to the current date- With context
<User>
### Context: Today is Saturday <-- Injected context -->
### Question: What day is tomorrow?
<LLM Response>
### SundayJust by adding relevant context we are able to
- Reduce Hallucinations Help LLMs avoid generating factually incorrect or misleading information.
- Enhanced informativeness: RAG can help LLMs generate more comprehensive and informative responses.
- Provide latest knowledge: Provide LLMs with up-to-date and proprietary knowledge that wasn’t included in its training data.
- Flexibility: The LLMs and the knowledgebase are independent of each other and can be easily updated or replaced.
Before building a RAG system
One must consider various factors before developing a useable RAG system.
-
Define you task and knowledge sources: What is the intended use case? How will the end user use it? This could be anything from writing a factual summary of a topic to generating creative text formats based on specific information.
Defining your knowledge sources is equally crucial. Does your use case involve internal documentation that are rarely updated or does it involve streams of data that must be continuously updated?
-
Choosing your models and databases: The current LLMs are rapidly evolving with both proprietary and open source models on rise. Each of them have different strengths and weakness. You must carefully choose a model that is suitable for your use case as it will greatly affect the quality of the end-results.
While all vector databases serve the same purpose, their implementation and design decisions will affect your choice for your use case. Your choice of knowledge sources will dictate how the data will be inserted and updated in your databases.
-
Data Ingestion With the amount of different files types, there isn’t a single defined approach for ingesting everything. Most of the time the data isn’t ideal for ingestion so setting a proper pre-processing pipeline is necessary. Most of the vector databases allow multiple app. Depending on the type of data different approaches may be applicable.
-
Data Retrieval While simply searching the database may work for QA applications, many times the results are far from ideal and unusable. Techniques like Summarization of documents, storing additional metadata, Re-ranking, fine-tuning llm models , agents, etc. can help us improve our results. Instead of a linear approach involving a single LLM call, we can use multiple LLM calls to implement a chains of thought approach.
Wrapping up
This is just a brief overview of what RAG systems are and how they work. Overall, RAG holds promise in overcoming the limitations of LLMs, enabling them to generate more accurate and comprehensive responses across diverse applications and domains.
While building a RAG system may sound simple there are various design decisions that affects the overall quality of the systems and with the AI landscape constantly evolving the choices made should be future proof allowing integration of the latest technology.