Implementing a Simple BPE Tokenizer in .NET
Writing a basic Byte Pair Encoding (BPE) tokenizer using C# and .NET
In our previous blog post, we discussed about tokenization in large language models (LLMs). Today, we will be implementing a simple tokenizer in C# using the Byte Pair Encoding (BPE) algorithm.
Our goal is to train a tokenizer on a sample dataset and use the trained tokenizer to encode and decode an input text. While this will be a basic implementation, it serves as an excellent starting point to understand how tokenization is used in modern apps.
What is Byte Pair Encoding (BPE)?
In the context of tokenization for large language models (LLMs), Byte Pair Encoding (BPE) is a technique used to iteratively merge the most frequent pairs of characters or subwords to create new tokens.
This process starts with a basic tokenization where each character or subword is treated as a token. By identifying and merging the most frequent pairs, BPE reduces the number of tokens needed to represent text, making processing more efficient.
This method also provides flexibility in handling rare and out-of-vocabulary words by breaking them down into subwords, thereby enhancing the model’s ability to process large amounts of text data effectively.
Here’s an example that shows the BPE algorithm in action
Sentence: "look at the book"
1. Initial Tokenization:
Tokens: ['l', 'o', 'o', 'k', ' ', 'a', 't', ' ', 't', 'h', 'e', ' ', 'b', 'o', 'o', 'k']
2. Counting Duplicate Pairs:
Duplicate Pairs:
- ('o', 'o') (occurs twice)
3. Merging Duplicate Pairs:
- Merge ('o', 'o') → ['l', 'oo', 'k', ' ', 'a', 't', ' ', 't', 'h', 'e', ' ', 'b', 'oo', 'k']
- Merge ('oo', 'k') → ['l', 'ook', ' ', 'a', 't', ' ', 't', 'h', 'e', ' ', 'b', 'ook']
4. Final Tokens:
Tokens: ['l', 'ook', ' ', 'a', 't', ' ', 't', 'h', 'e', ' ', 'b', 'ook']Implementation
Let’s start with a SimpleTokenizer class that will contain the core functionality of our BPE tokenizer.
public class SimpleTokenizer
{
/// Dictionary to store the vocabulary, mapping tokens to their unique IDs.
private readonly Dictionary<string, int> _vocabulary = new Dictionary<string,int>();
/// Counter to keep track of the next available token ID.
private int _nextTokenId = 0 ;
}The _vocabulary dictionary stores a vocabulary where each token is mapped to a unique Token ID. The vocabulary will be case-sensitive, preserving the exact form of the input token (e.g., a and A are treated as different tokens).
The _nextTokenId variable keeps track of the next available ID when adding new tokens to the vocabulary.
The tokens can be a single character, subword, full word, or special tokens. Special tokens act as meta characters that indicate specific scenarios. For example, vocabularies include tokens that define clear boundaries between sentences, such as “Start of Text” and “End of Text” tokens. These tokens help language models understand text structure and perform various NLP tasks effectively.
Remember that the language models never work with raw text but rather the token representation based on a vocabulary both for training and inference.
We will now implement the following methods for our tokenizer class:
AddToken: Add a new token to the vocabularyEncode: Convert input text into a sequence of token IDsDecode: Convert a sequence of token IDs back into textTrain: Implement the BPE algorithm to build the vocabulary from a dataset
Let’s start with the AddToVocabulary method.
/// <summary>
/// Adds a new token to the vocabulary if it doesn't already exist.
/// </summary>
/// <param name="token">The token to add to the vocabulary.</param>
public void AddToVocabulary(string token)
{
// If the token is not in the vocabulary, add it with a new unique ID
if (!_vocabulary.ContainsKey(token))
{
_vocabulary[token] = _nextTokenId++;
}
}Here we are just adding the given input to our dictionary if it doesn’t already exist and incrementing the next token ID.
Training the Tokenizer
During the training, we iteratively find the most frequent pair of tokens and merge them into a new token using the byte pair encoding algorithm. We will avoid generating tokens with spaces in between them so that we don’t merge two separate words as one token.
Here’s the implementation for getting the most frequent pairs.
/// <summary>
/// Finds the most frequent pair of tokens in the given texts.
/// This is a helper method used in the training process.
/// </summary>
/// <param name="textData">The tokenized training data</param>
/// <returns>A tuple containing the most frequent pair of tokens, or null if no pairs are found.</returns>
private Tuple<string, string> GetMostFrequentPair(string textData)
{
var pairCounts = new Dictionary<Tuple<string, string>, int>();
var tokens = Tokenize(textData);
for (int i = 0; i < tokens.Count - 1; i++)
{
var pair = Tuple.Create(tokens[i], tokens[i + 1]);
// Skip pairs with empty tokens or invalid pairs
// We only want spaces at the start of our tokens not in between
if (string.IsNullOrWhiteSpace(pair.Item2) ||
(pair.Item1.Contains(" ") && !pair.Item1.StartsWith(" ")) ||
pair.Item2.Contains(" "))
{
continue;
}
// Count the occurrences of each pair
if (!pairCounts.ContainsKey(pair))
pairCounts[pair] = 0;
pairCounts[pair]++;
}
// If no pairs are found, return null
if (pairCounts.Count == 0)
return Tuple.Create<string, string>(null, null);
// Return the most frequent pair
return pairCounts.OrderByDescending(p => p.Value).First().Key;
}
Our training method for generating the vocabulary based on a given dataset
/// <summary>
/// Trains the tokenizer on a list of texts, merging frequent pairs up to maxMerges times.
/// This method implements the core learning process of the tokenizer.
/// </summary>
/// <param name="texts">The list of texts to train on.</param>
/// <param name="maxMerges">The maximum number of merges to perform. ie new tokens to add</param>
public void Train(List<string> texts, int maxMerges)
{
// Set to keep track of merged pairs to avoid duplicates
var mergedPairs = new HashSet<string>();
for (int i = 0; i < maxMerges; i++)
{
string text = string.Join("", texts);
// Find the most frequent pair of tokens in the texts
var pairs = GetMostFrequentPair(text);
// If no pairs are found, exit the training loop
if (pairs.Item1 == null)
{
Console.WriteLine("No more pairs to merge. Exiting.");
break;
}
// Create a new token by concatenating the pair
string newToken = pairs.Item1 + pairs.Item2;
// Check if this pair has already been merged
if (mergedPairs.Contains(newToken))
{
Console.WriteLine($"Skipping already merged pair: ({pairs.Item1}, {pairs.Item2})");
continue;
}
// Add the new token to the vocabulary
AddToVocabulary(newToken);
mergedPairs.Add(newToken);
// Replace all occurrences of the pair with the new token in all texts
for (int j = 0; j < texts.Count; j++)
{
texts[j] = texts[j].Replace(pairs.Item1 + pairs.Item2, newToken);
}
}
}This method takes a list of training texts and the number of merges to perform. It repeatedly finds the most frequent pair of tokens, creates a new token by merging them, and updates the vocabulary and training texts accordingly.
Here we are maintaining the vocabulary in memory, but in real life scenarios this training is only done once and the vocabulary is saved as a checkpoint. The language models are then trained on the finilized vocabulary depending on the training objective.
Tokenizing and Encoding
Once our tokenizer is trained, we can use it to tokenize and encode new text:
/// <summary>
/// Tokenizes a given text using the learned vocabulary.
/// </summary>
/// <param name="text">The text to tokenize.</param>
/// <returns>A list of tokens.</returns>
public List<string> Tokenize(string text)
{
var tokens = new List<string>();
int i = 0;
while (i < text.Length)
{
string bestToken = null;
// Find the longest matching token in the vocabulary
foreach (var token in _vocabulary.Keys)
{
if (text.Substring(i).StartsWith(token) && (bestToken == null || token.Length > bestToken.Length))
{
bestToken = token;
}
}
// If a matching token is found, add it to the result
if (bestToken != null)
{
tokens.Add(bestToken);
i += bestToken.Length;
}
else
{
// If no match is found, add the current character as a single-character token
tokens.Add(text[i].ToString());
i++;
}
}
return tokens;
}/// <summary>
/// Encodes a text into a list of token IDs.
/// </summary>
/// <param name="text">The text to encode.</param>
/// <returns>A list of token IDs.</returns>
public List<int> Encode(string text)
{
// First tokenize the text, then convert each token to its ID
var tokens = Tokenize(text);
return tokens.Select(t => _vocabulary[t]).ToList();
}The Tokenize method breaks down the input text into tokens based on our vocabulary, while the Encode method converts these tokens into their corresponding IDs.
Decoding
For decoding, we take the encoded input and match it with our trained vocabulary to get the text output.
public string Decode(List<int> ids)
{
var inverseVocab = vocabulary.ToDictionary(kvp => kvp.Value, kvp => kvp.Key);
return string.Join("", ids.Select(id => inverseVocab[id]));
}Using the Tokenizer
Now that we have implemented the tokenizer, here’s how we can use it
First, we are manually adding individual characters to our vocabulary as a baseline. This ensures we can tokenize any text, even if it contains characters outside the given training data.
var tokenizer = new SimpleTokenizer();
// Initialize vocabulary
string chars = " ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*()_+-=[]{}|;:'\",.<>?/";
foreach (char c in chars)
{
tokenizer.AddToVocabulary(c.ToString());
}Next, we train the tokenizer based on sample data. Here we are just using some text for faster training. In real scenarios, this data is much larger and curated for obtaining the desired tokenization.
// Training data
var trainingTexts = new List<string> { "the rabbit was very fast",
"A Hare was making fun of the Tortoise one day for being so slow.\r\n\r\n\"Do you ever get anywhere?\" he asked with a mocking laugh.\r\n\r\n\"Yes,\" replied the Tortoise, \"and I get there sooner than you think. I'll run you a race and prove it.\"\r\n\r\nThe Hare was much amused at the idea of running a race with the Tortoise, but for the fun of the thing he agreed. So the Fox, who had consented to act as judge, marked the distance and started the runners off.\r\n\r\nThe Hare was soon far out of sight, and to make the Tortoise feel very deeply how ridiculous it was for him to try a race with a Hare, he lay down beside the course to take a nap until the Tortoise should catch up.\r\n\r\n\r\nThe Tortoise meanwhile kept going slowly but steadily, and, after a time, passed the place where the Hare was sleeping. But the Hare slept on very peacefully; and when at last he did wake up, the Tortoise was near the goal. The Hare now ran his swiftest, but he could not overtake the Tortoise in time.",};
string inputText = "A rabbit was sleeping peacefully";
Console.WriteLine($"--------------------------Before Training--------------------------");
PrintTokens(tokenizer,inputText);
static void PrintTokens(SimpleTokenizer tokenizer, string inputText){
//Display implementation
}The PrintToken function just helps to better visualize the results on the console.
Let’s see the output before we start training our tokenizer.

I have replaced the spaces with a _ for better visualization.
And now the training loop
Console.WriteLine($"--------------------------Training--------------------------");
int newTokens = 10;
int merges = 10;
int loops = 10;
while (loops > 0)
{
tokenizer.Train(trainingTexts, 10);
Console.WriteLine($"Added {merges} new Tokens");
PrintTokens(tokenizer, inputText);
merges += 10;
loops--;
}Here we are printing the results every time 10 new tokens are added up to 100 new tokens. Below are some of the output results.
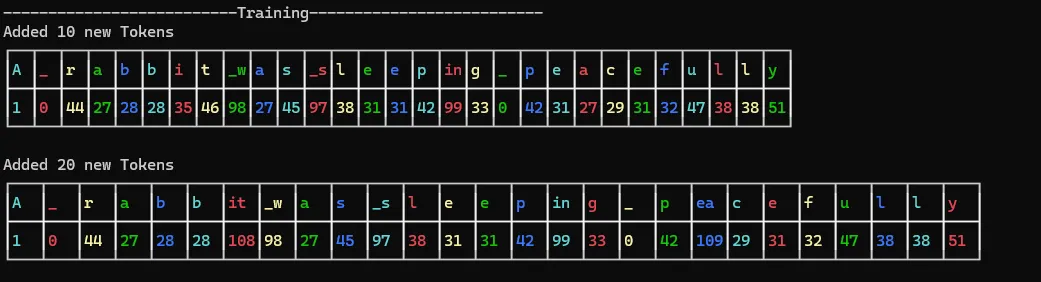

With every loop, the tokenizer gets better at segmenting the text in a way that optimizes
the patterns in the training data. Since the original data was a story about a rabbit and tortoise, the word _rabbit was converted to a single token.
Conclusion
We have successfully implemented a simple Byte Pair Encoding (BPE) tokenizer in .NET, demonstrating the process of creating a SimpleTokenizer class, building and managing a vocabulary, and training the tokenizer using the BPE algorithm.
With tokenization, text is broken down into manageable pieces, making it easier for models to understand and process, which boosts performance and accuracy. The BPE algorithm helps by merging the most frequent subwords, ensuring that the model captures the important parts of the text.