
Building a Simple text Classifier with Semantic Kernel
Using Semantic kernel to showcase how NLP tasks like text classification can be done with just a bit of prompt engineering in both python and .NET
Semantic Kernel is an open-source orchestration framework that helps developers integrate AI Large Language Models (LLMs) into their applications with ease. In this blog post, we’ll explore how to use Semantic Kernel to build a simple Natural Language Processing (NLP) classifier.
What is Semantic Kernel?
Semantic Kernel acts as a bridge between your application and various AI models. It provides a common abstraction for working with different AI services, making it easier to switch between models or combine multiple models in your application.
What are Large Language Models (LLMs)?
Large Language Models are AI models trained on large amounts of data. They can understand and generate human-like text, and perform various language tasks. Some popular examples include OpenAI’s GPT family, Llama , Gemini, and Claude.
Our Classification Task
Our goal is to create a straightforward classifier that categorizes a given piece of text into one of the following categories:
- Historical
- Anecdote
- Folklore
- Fiction
- Unknown
This is an arbitrary list that the LLMs models weren’t exactly trained for but due to these being general concepts the current models should be able to classify them without much issue.
A domain-specific classification will be more challenging but can be somewhat feasible with better prompt engineering.
Depending on the AI model licensing terms we could even use these outputs to generate high-quality syntenic datasets to train a smaller specialized model for our task potentially reducing overall costs.
I will be showcasing both the .NET and python SDKs to showcase this example.
Semantic kernel .NET SDK
Let’s start with the .NET version.
We will be focusing on the Semantic kernel part of the app. This app generates a classification result based on the text input and a selected prompt template.
Make sure to add the latest Microsoft.SemanticKernel nuget package.
dotnet add package Microsoft.SemanticKernelWe will be starting with the Kernel. The kernel is a lightweight object, containing all our registered AI services, plugins, etc. We interact with our AI services through the kernel.
Now time to define our kernel.
IKernelBuilder builder = Kernel.CreateBuilder();
builder.AddAzureOpenAIChatCompletion("DeploymentName", "Endpoint","APIKEY", "YourCustomServiceId");
Kernel kernel = builder.Build();Here we are using Azure OpenAI as an example but there are multiple other connectors available from other providers like Gemini, HuggingFace, or local model inference like Ollama. Checkout the Github repo to see the latest available connectors
Writing Prompts
Next, we are going to define our prompt templates.
Prompts can heavily influence the AI-generated outputs. Well-written prompts can greatly improve the LLM’s performance, but bad prompts may even decrease its performance. But why is that?
LLMS are statistical models built for general use. While they may seem intelligent at one glance, under the hood they don’t understand any of the words they say. As we clearly define our input prompt, the more likely it is to generate the desired output.
Here I have defined basic prompt templates using the default “semantic-kernel” template format.
You can find more info about the default semantic kernel syntax here
1. Simple
Classify the following text: {{$request}}Here we are just asking the LLM for a response without specifying anything. This will give us different types of responses for each call. While this may be desired for some use cases for our task this will give inconsistent results.
2. Specific
Classify the following text as one of the following: Historical, Anecdote, Folklore, Fiction, Unknown.
Text: {{$request}}Here we are limiting our categories for classifying by being more specific. This limits the LLM responses and gives us the expected outputs.
3. Structured
Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: This template separates the instructions and user input along with specifying a set of choices. The “Type:” at the end encourages the LLM to provide its answer in a specific format, which can make parsing the response easier and more consistent.
4. Few Shot examples
Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: The American Revolution began in 1775.
Type: Historical
User Input: I once saw a shooting star while camping.
Type: Anecdote
User Input: The legend of Robin Hood stealing from the rich to give to the poor.
Type: Folklore
User Input: Harry Potter is a young wizard who attends Hogwarts School of Witchcraft and Wizardry.
Type: Fiction
User Input: The quantum properties of dark matter.
Type: Unknown
User Input: {{$request}}
Type: This approach uses few-shot learning, where you provide examples of each category before asking for the classification of the new input. This can significantly improve the accuracy of the LLM’s classification, especially for edge cases or less common types of text.
5. Avoid Guessing
Instructions: Classify the following text. If you don't know the type or it doesn't fit the given categories, respond with "Unknown".
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: This prompt prevents the LLM from guessing when it’s unsure. By explicitly instructing it to use “Unknown” when it can’t confidently classify the text, you’re likely to get more accurate results and avoid misclassifications.
Each of these approaches has its strengths:
- Specific is more focused than Simple but still relatively concise.
- Structured provides a clear format for the response.
- FewShot can improve accuracy through example-based learning.
- Avoid Guessing helps prevent misclassifications when the LLM is uncertain.
Here I have defined a custom Enum for the above Prompt types and added them in a dictionary.
public enum PromptType
{
Simple,
Specific,
Structured,
FewShot,
AvoidGuessing
}
var prompts = new Dictionary<PromptType, string>
{
{ PromptType.Simple, "Classify the following text: {{$request}}" },
{ PromptType.Specific, "Classify the following text as one of the following: Historical, Anecdote, Folklore, Fiction, Unknown.\nText: {{$request}}" },
{ PromptType.Structured, "Instructions: Classify the following text as one of the following types:\nChoices: Historical, Anecdote, Folklore, Fiction, Unknown.\nUser Input: {{$request}}\nType: " },
{ PromptType.FewShot, @"Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: The American Revolution began in 1775.
Type: Historical
User Input: I once saw a shooting star while camping.
Type: Anecdote
User Input: The legend of Robin Hood stealing from the rich to give to the poor.
Type: Folklore
User Input: Harry Potter is a young wizard who attends Hogwarts School of Witchcraft and Wizardry.
Type: Fiction
User Input: The quantum properties of dark matter.
Type: Unknown
User Input: {{$request}}
Type: " },
{ PromptType.AvoidGuessing, @"Instructions: Classify the following text. If you don't know the type or it doesn't fit the given categories, respond with ""Unknown"".
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: " }
};
Making the AI calls
Let’s define the input text we want to classify.
Here I am using a popular fictional quote from the book The Hitchhiker's Guide to the Galaxy as an example.
string input = "The answer to the Ultimate Question of Life, the Universe, and Everything is 42";Pass the selected input through the KernelArguments as a variable.
Make sure that the Template variable and Kernel argument are the same. In this case, we are using request.
//Pass in the input as kernel arguments
KernelArguments args = new KernelArguments() { { "request", input } };Select a prompt template from the above prompts.
//Select a template
PromptType selectedPrompt = PromptType.Specific
string promptTemplate = _prompts[promptType];Now we can finally make the AI call through our kernel with the selected template and arguments.
//Make the AI call and get the response
FunctionResult result = await _kernel.InvokePromptAsync(promptTemplate, args);
string aiResponse = result.GetValue<string>()That’s all the code required to complete our initial task.
Note that we haven’t used any Azure OpenAI-specific code except when registering it as a service, so we could easily te.
I have also built a demo app with the above logic using Blazor.
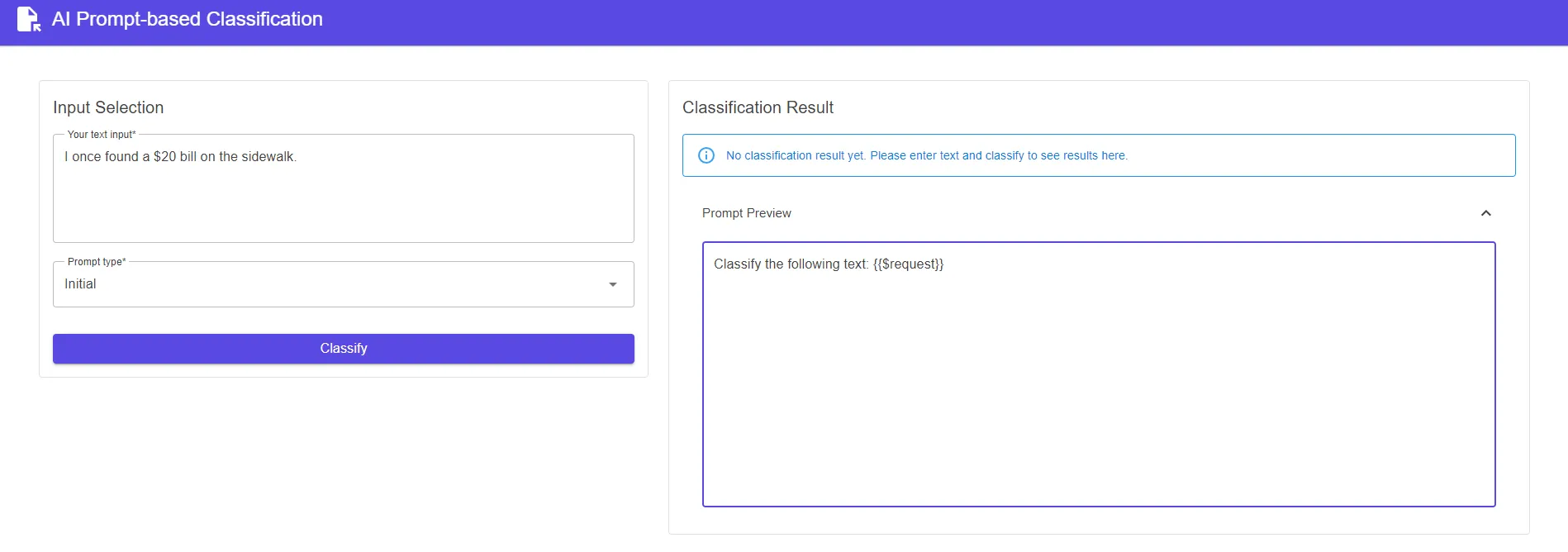
Python SDK
The python implementation for this task is very similar with some minor differences.
First, install the semantic-kernel package.
pip install semantic-kernelImport the required modules, Here we are using Azure OpenAI.
from semantic_kernel import Kernel
from semantic_kernel.functions import KernelArguments
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletionNext, define the kernel and add the required service.
kernel = Kernel()
azureOpenAIService = AzureChatCompletion("YourCustomServiceID","APIKEY","DEPLOYMENTNAME","Base_URL")
kernel.add_service(azureOpenAIService)Next, define our prompt templates.
prompts = {
"Initial": "Classify the following text: {{$request}}",
"Specific": """Classify the following text as one of the following: Historical, Anecdote, Folklore, Fiction, Unknown.
Text: {{$request}}""",
"Structured": """Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: """,
"Few-shot": """Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: The American Revolution began in 1775.
Type: Historical
User Input: I once saw a shooting star while camping.
Type: Anecdote
User Input: The legend of Robin Hood stealing from the rich to give to the poor.
Type: Folklore
User Input: Harry Potter is a young wizard who attends Hogwarts School of Witchcraft and Wizardry.
Type: Fiction
User Input: The quantum properties of dark matter.
Type: Unknown
User Input: {{$request}}
Type: """,
"Avoid guessing": """Instructions: Classify the following text. If you don't know the type or it doesn't fit the given categories, respond with "Unknown".
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: """
}Next, define our request and pass it through the kernelArguments, along with selecting a prompt template.
request = "The answer to the Ultimate Question of Life, the Universe, and Everything is 42"
arguments = KernelArguments(request=request)
promptType = "Structured"And finally, call our AI service through the kernel.
result = await kernel.invoke_prompt(
function_name=f"textClassifier",
plugin_name="textClassifierPlugin",
prompt=prompts[prompt_type],
arguments=arguments
)This code is functionally identical to our above .NET code.
Here’s a sample app written in python using the Semantic kernel SDK and gradio library.
import gradio as gr
import asyncio
import logging
from semantic_kernel import Kernel
from semantic_kernel.functions import KernelArguments
from semantic_kernel.connectors.ai.open_ai import AzureChatCompletion
# from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion
logger = logging.getLogger(__name__)
logging.basicConfig(level=logging.INFO)
##Define the kernel and add the required service
kernel = Kernel()
azureOpenAIService = AzureChatCompletion("YourCustomServiceID","APIKEY","DEPLOYMENTNAME","Base_URL")
kernel.add_service(azureOpenAIService)
## Can also use OpenAI or Huggingface models
# openAIService = OpenAIChatCompletion("AIModel","YourCustomServiceID","APIKEY")
# kernel.add_service(openAIService)
## Here we are defining the prompt templates in a dictionary
prompts = {
"Initial": "Classify the following text: {{$request}}",
"Specific": """Classify the following text as one of the following: Historical, Anecdote, Folklore, Fiction, Unknown.
Text: {{$request}}""",
"Structured": """Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: """,
"Few-shot": """Instructions: Classify the following text as one of the following types:
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: The American Revolution began in 1775.
Type: Historical
User Input: I once saw a shooting star while camping.
Type: Anecdote
User Input: The legend of Robin Hood stealing from the rich to give to the poor.
Type: Folklore
User Input: Harry Potter is a young wizard who attends Hogwarts School of Witchcraft and Wizardry.
Type: Fiction
User Input: The quantum properties of dark matter.
Type: Unknown
User Input: {{$request}}
Type: """,
"Avoid guessing": """Instructions: Classify the following text. If you don't know the type or it doesn't fit the given categories, respond with "Unknown".
Choices: Historical, Anecdote, Folklore, Fiction, Unknown.
User Input: {{$request}}
Type: """
}
async def process_request(request, prompt_type):
if not request.strip():
return "Error: The request cannot be empty. Please enter some text to classify."
arguments = KernelArguments(request=request)
logger.info(f"Processing request: {request} with prompt type: {prompt_type}")
try:
result = await kernel.invoke_prompt(
function_name=f"sample",
plugin_name="sample_plugin",
prompt=prompts[prompt_type],
arguments=arguments
)
logger.info(f"Result: {result}")
except Exception as e:
logger.error(f"Error processing request: {e}")
result = "Error processing request"
return result
def gradio_interface(request, prompt_type):
return asyncio.run(process_request(request, prompt_type))
def update_preview(prompt_type):
return prompts[prompt_type]
with gr.Blocks(theme=gr.themes.Soft()) as iface:
gr.Markdown("# Narrative Genre Analyzer")
gr.Markdown("Categorize text into Historical, Anecdote, Folklore, Fiction, or Unknown. Choose a prompt strategy and enter your text to analyze its genre.")
with gr.Row():
with gr.Column():
input_text = gr.Textbox(label="Your text input", placeholder="Enter the text to classify...", lines=5)
prompt_type = gr.Radio(
["Initial", "Specific", "Structured", "Few-shot", "Avoid guessing"],
label="Prompt type",
info="Select the prompt type to use for classification.",
value = "Initial"
)
submit_button = gr.Button("Classify")
with gr.Column():
output_text = gr.Textbox(label="Classification Result")
preview_text = gr.Textbox(label="Prompt Preview", lines=10)
prompt_type.change(fn=update_preview, inputs=prompt_type, outputs=preview_text)
submit_button.click(fn=gradio_interface, inputs=[input_text, prompt_type], outputs=output_text)
gr.Examples(
examples=[
["The Wright brothers made their first successful flight in 1903.", "Few-shot"],
["My grandmother always told me stories about a magical forest near our village.", "Avoid guessing"],
["I once found a $20 bill on the sidewalk.", "Initial"],
["In a galaxy far, far away, there was a young Jedi named Luke Skywalker.", "Specific"],
["The Great Wall of China was built over many centuries.", "Structured"],
["The Loch Ness Monster is said to inhabit the depths of a Scottish lake.", "Few-shot"],
["I'm not sure if this is true, but I heard that eating carrots improves night vision.", "Avoid guessing"]
],
inputs=[input_text, prompt_type]
)
iface.launch()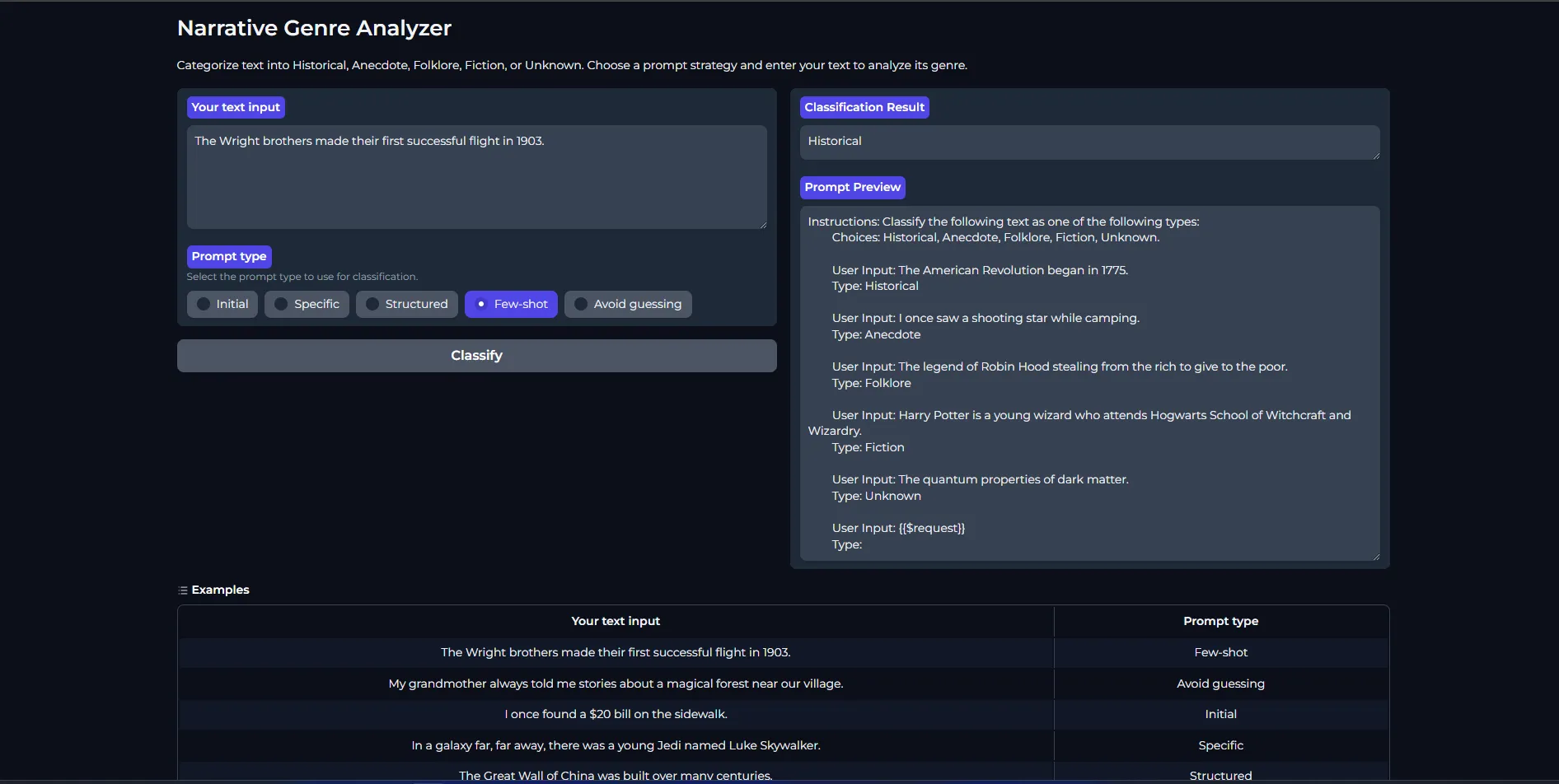
Wrapping up
In this post, we’ve seen how to use the Semantic Kernel SDK to build a simple text classifier. This approach demonstrates how to seamlessly integrate AI features into existing codebases with minimal overhead, allowing developers to enhance their applications without significant restructuring.
But remember that while implementing these LLM models can be relatively straightforward, understanding their capabilities and limitations is key to using them effectively. The examples we’ve covered barely scratch the surface of what’s possible with current AI technologies.
As the field of AI rapidly evolves, we may see paradigm shifts that fundamentally change how we approach these technologies. Developers should stay informed about the latest advancements and be prepared to adapt their implementations accordingly.