
Building AI Apps with .Net Aspire and Semantic Kernel
Using aspire orchestration to develop AI-powered apps locally with .NET and Semantic Kernel
Introduction
In the previous blog, we saw an overview of what .NET Aspire is and how we can use it.
With the current development of AI apps, we are seeing a more distributed approach. Sure while it’s possible to connect various services this isn’t a trivial problem.
This is where Aspire tries to simplify the development process so developers can focus on writing business logic rather than having to set up and manage all the networking just for running the apps locally.
Now let’s see how we can use Aspire to connect different apps and build a sample distributed solution. Let’s build a speech-to-text app with .NET, semantic kernel, and local whisper service.
But what is Semantic Kernel?
Semantic Kernel is a .NET SDK that simplifies the integration of various AI services and frameworks. It provides abstractions and orchestration for different AI modalities like text, image, and audio making it easier to integrate these functionalities into your applications.
Building a Speech-to-Text App with Aspire
We will be including the following things in our aspire project
- A .NET application with Semantic Kernel SDK (frontend)
- A local Whisper server image for inference (
fedirz/faster-whisper-server:latest-cpu)
Running this project would also require an active container runtime like docker.
Since we are using Local inference we won’t need any API keys. You can also any number of images or projects to this solution if required.
NOTE: For existing .NET projects we can easily add Aspire orchestration supports either through UI.
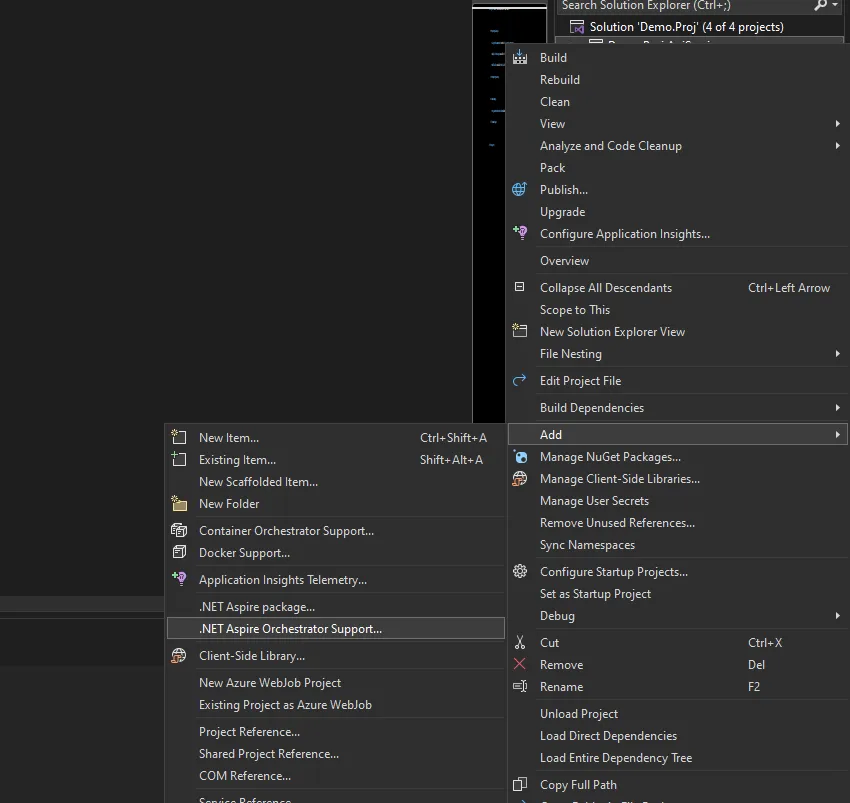
This step can also be done manually instead of relying on the UI.
Adding the .NET Aspire support just registers the Services defaults in our .NET project like OpenTelemetry and health checks along with adding the Project reference in our aspire project.
Frontend
For the frontend, I am using a .NET app along with aspiring Orchestrator Support added.
The app accepts user speech or audio files as input and delivers the transcribed text as output.
For Audio transcriptions Semantic Kernel offers built-in options like OpenAI and Azure OpenAI accessible through the IAudioToTextService interface.
Here is a quick custom implementation of the IAudioToTextService.
public class LocalSpeechToTextService : IAudioToTextService
{
private readonly HttpClient _client;
private static readonly Dictionary<string, object?> dictionary = new Dictionary<string, object?>();
internal Dictionary<string, object?> _attributes { get; } = dictionary;
IReadOnlyDictionary<string, object?> IAIService.Attributes => _attributes;
private string _model;
public LocalSpeechToTextService(HttpClient client, IConfiguration config)
{
_client = client;
_model = config.GetValue<string>("WHISPER_MODEL") ?? string.Empty;
}
public async Task<IReadOnlyList<TextContent>> GetTextContentsAsync(AudioContent content, PromptExecutionSettings? executionSettings = null, Kernel? kernel = null, CancellationToken cancellationToken = default)
{
ReadOnlyMemory<byte> audioData = content.Data.Value;
var byteArray = audioData.ToArray();
var fileContent = new ByteArrayContent(byteArray);
var formData = new MultipartFormDataContent
{
{ fileContent, "file", "file" },
{ new StringContent(_model), "model" },
{ new StringContent("en"), "language" },
{ new StringContent("text"), "response_format" },
{ new StringContent("0.0"), "temperature" },
};
var response = await _client.PostAsync("/v1/audio/transcriptions", formData, cancellationToken);
var responseString = await response.Content.ReadAsStringAsync(cancellationToken);
return new List<TextContent>() { new TextContent(responseString) };
}
}We are simply making an http call to our local whisper server and returning the response. We are also adding an extension method for easily using it with our kernel.
public static class LocalSpeechToTextExtension
{
public static IKernelBuilder AddCustomSpeechToText(
this IKernelBuilder builder, LocalSpeechToTextService localSpeechToText, string serviceId = "localSpeechToText")
{
builder.Services.AddKeyedSingleton<IAudioToTextService>(serviceId, implementationInstance: localSpeechToText);
return builder;
}
}Now that we have our local implementation set up it’s time to register our services in our projects Program.cs .
builder.Services.AddSingleton<LocalSpeechToTextService>();
builder.Services.AddHttpClient<LocalSpeechToTextService>(client =>
{
client.BaseAddress = new Uri(config.GetValue<string>("services:whisper:http:0")!);
});The services:whisper:http:0 is the URL for our local whisper server we will be setting up in our Aspire Project.
Aspire Apphost
Finally, we will be defining and connecting our apps in the Aspire.Apphost’s Program.cs
var builder = DistributedApplication.CreateBuilder(args);
#region whisper-server
var fastWhisperServer = builder.AddContainer("whisper", "fedirz/faster-whisper-server", "latest-cpu")
.WithHttpEndpoint(port: 52217 ,targetPort: 8000, name: "http")
.WithEnvironment("WHISPER_MODEL", "Systran/faster-distil-whisper-small.en")
.WithVolume("cache", "/root/.cache/huggingface")
var fastWhipserEndpoint = fastWhisperServer.GetEndpoint("http");
#endregion
var frontend = builder.AddProject<Projects.Frontend>("frontend")
.WithReference(fastWhipserEndpoint)
.WithEnvironment("WHISPER_MODEL", "Systran/faster-distil-whisper-small.en");
builder.Build().Run();Let’s look at it part by part.
var fastWhisperServer = builder.AddContainer("whisper", "fedirz/faster-whisper-server", "latest-cpu")
.WithHttpEndpoint(port: 52217 ,targetPort: 8000, name: "http")
.WithEnvironment("WHISPER_MODEL", "Systran/faster-distil-whisper-small.en")
.WithVolume("cache", "/root/.cache/huggingface")Since the faster-whisper-server image isn’t directly supported by the Aspire team we will be using the generic API for adding our image and exposing it as an http endpoint.
We are targeting port 8000 (the default Port used by faster-whisper-server container) and mapping it to a specific port on the system (in this case 52217)
.WithHttpEndpoint(port: 52217 ,targetPort: 8000, name: "http")
```
If you have used docker you might already be familiar with volume. Here we are defining a persistent storage in the `cache` folder to store our whisper model and reuse it whenever we run our app.
```csharp
.WithVolume("cache", "/root/.cache/huggingface")Aspire allows us to pass environment variables in our containers.
We are setting the config WHISPER_MODEL to use the Systran/faster-distil-whisper-small.en available on huggingFace. This is a container-related config and will be different based on the container.
var fastWhipserEndpoint = fastWhisperServer.GetEndpoint("http");
var frontend = builder.AddProject<Projects.Frontend>("frontend")
.WithReference(fastWhipserEndpoint)
.WithEnvironment("WHISPER_MODEL", "Systran/faster-distil-whisper-small.en");Next, we are adding our frontend app along with the reference to our fastWhisperServer http endpoint. We can now access it in our app by getting the following config value services:<serviceName>:<endpointName>:<Instance>.
We are also setting a custom environment variable WHISPER_MODEL passing the same model name as our server Systran/faster-distil-whisper-small.en.
Now when we run this solution we should see the following services up.

Here’s the sample frontend app built based on the above code.
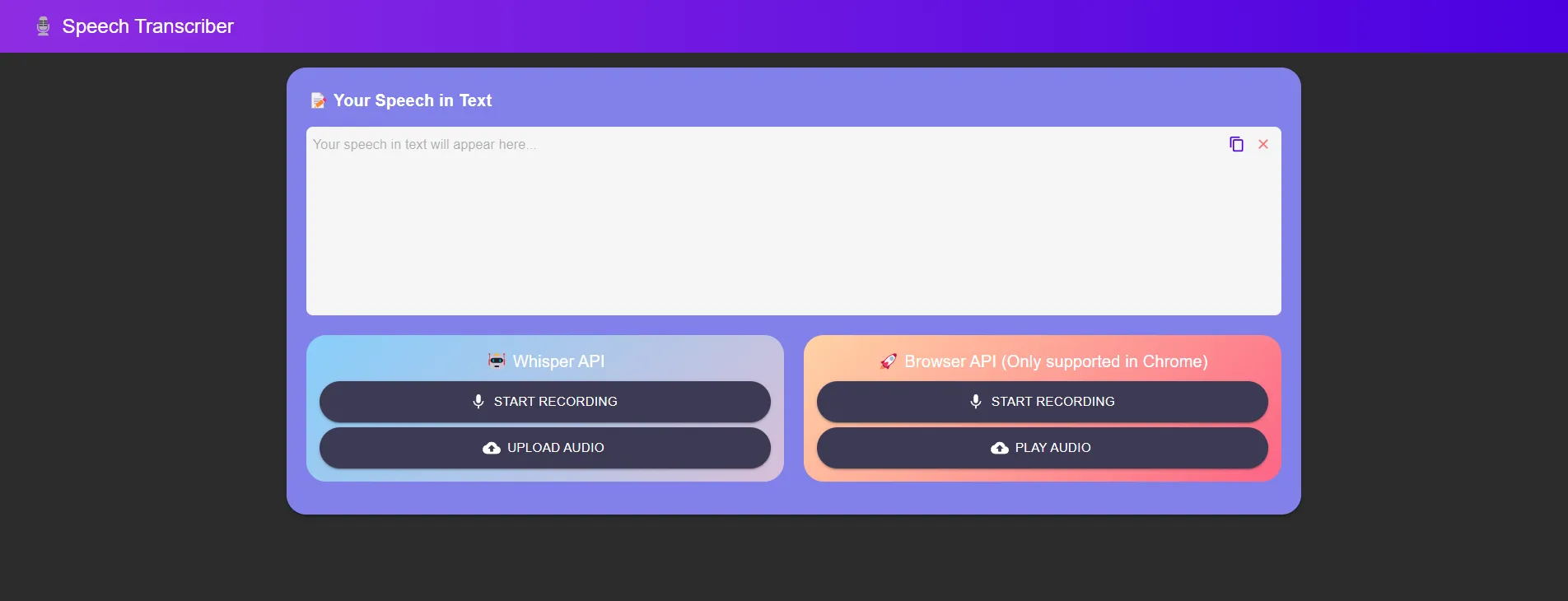
You can check out the demo here Speech to text demo
The app has two speech-to-text options one with the whisper instance running on the local server and the other is the WebSpeech Browser API currently available on specific client-browsers.
While the whisper-small model isn’t the best-performing model compared to the bigger models it still gives us great results. But when we compare the browser API to whisper models the whisper-small model vastly outperforms it.
Wrapping Up
This blog post has demonstrated how to use .NET Aspire and Semantic Kernel to construct a speech-to-text application with local inference. Aspire aims to simplify development and streamline the process of creating cloud-native applications.