
Introduction to Vector Databases
Introduction to Vector Databases, the next-gen DBMS powering AI applications.
 Yash Worlikar Tue Dec 05 2023 4 min read
Yash Worlikar Tue Dec 05 2023 4 min read What’s a vector database?
A Vector database is a type of database that is specialized for storing, indexing, and retrieving data in the form of vector embeddings.
Vector databases are designed to efficiently store and retrieve these vectors, making them well-suited for unstructured or semi-structured data, such as text, images, and audio. This flexibility makes them a very popular choice in AI applications.
Some well-known vector databases include:
- Qdrant - An open-source high-performance, massive-scale Vector Database with fully managed cloud hosting
- ChromaDB - An open-source lightweight vector database optimized for storing and querying high-dimensional vectors.
- Milvus - An open-source and cloud-native vector database ready for enterprise applications with multiple learning resources
- Pinecone - A proprietary cloud-based vector database that offers high availability and low latency.
- PostgreSQL with pgvector - An extension for PostgreSQL that adds vector storage and querying capabilities.
- Weaviate - Open-source vector search engine that combines vector search with structured filtering and offers cloud-native capabilities.
How does a vector database work?
Vector databases use embedding models to convert raw data into vector embeddings.
Embeddings are low-dimensional representations of complex objects like words or images. Words or sentences with similar meanings or semantic structures will be closer to one another.
The vector embeddings stored in the vector database aren’t just limited to text data, other types including documents, images, audio, and even videos can be stored as vector embeddings and queried efficiently.
Vector databases come pre-equipped with optimized search algorithms for quick retrieval and similarity searches with different types of distance metrics such as Euclidean Distance, Cosine Similarity, and Dot Product.
Here’s a simple example of how the vector database is used to retrieve data:
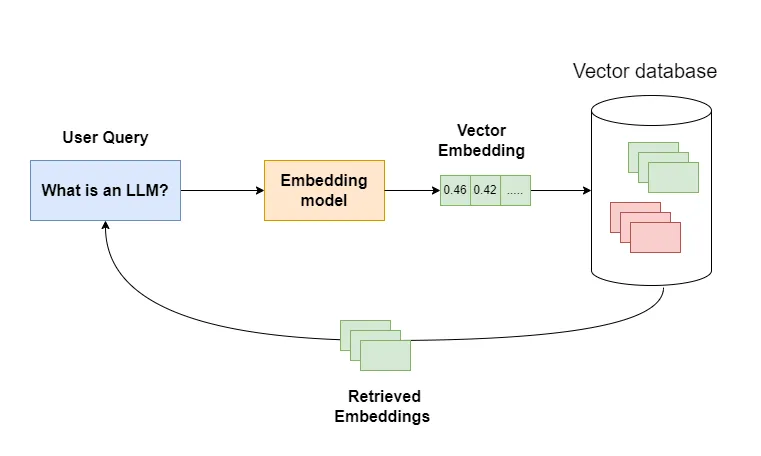
- When a user makes a query it first gets converted into a vector embedding using the embedding model.
- The converted embedding is then used to query against the database and retrieve the matching results based on specific criteria.
- The retrieved results are then sent back to the application for further processing.
- It is important to note that the Embedding model used for converting the database and user query must be the same. Using different embedding models for storing and querying will give nonsensical results.
Do you even need a vector database and when should you consider using one?
While vector databases are currently trending all over the place we should not just use them as a silver bullet. If you are already using a Database that supports vector search like PostgreSQL with pgvector extension introducing a dedicated vector database might just add unnecessary complexity.
A dedicated vector database starts being impactful as the number of embeddings grows. Smaller datasets might not fully leverage it’s advantages but the benefits become more apparent with larger datasets, especially when handling queries at scale
It is important to note that vector databases aren’t a replacement for traditional relational databases. They are specialized for similarity searches and do not guarantee ACID compliance.
Vector databases are well-suited for applications that require similarity search, such as:
-
Recommendation systems: They excel in suggesting products, movies, or other items to users by analyzing their past behavior or preferences
-
Image search: These databases represent images as vectors, enabling functions like image retrieval and classification.
-
Semantic Search: Vector databases power semantic search engines, comprehending search queries’ meanings and delivering context-based results beyond mere keyword matching.
-
Anomaly Detection: Leveraging known vectors, these databases enable us to identify outliers and unusual patterns in data, enhancing anomaly detection systems.”
The choice of using a dedicated vector database heavily depends on your use cases. Not just your current needs, but your future requirements as well.
The efficiency, scalability, and specific features of vector databases vary, and choosing the right one involves considering factors like query speed, storage capacity, and the ability to handle complex data structures. It’s not just about today’s demands; planning for future growth and functionality is crucial.