
Understanding LLMs and their workings
Understanding LLMs and their workings from the basics.
 Yash Worlikar Mon Dec 04 2023 4 min read
Yash Worlikar Mon Dec 04 2023 4 min read What is an LLM?
Large language models (LLMs) are machine learning models trained on massive amounts of data. Essentially, they’re supercharged autocomplete bots that predict the next word. Due to being trained on such a vast amount of data, the llms can learn and mimic the natural language and its patterns.
Despite their widespread popularity, these models are a kind of black box. The LLM models can consist of billions of parameters but what these parameters represent remains a mystery. Think of them as highly compressed versions of the data they were trained on.
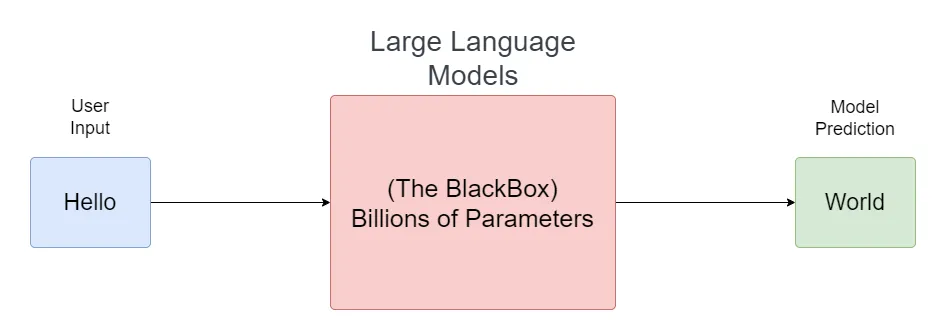
How LLMs Work
Now that we know what LLMs are, let’s see how they work.
For instance, let’s take an example of a user interacting with a simple chatbot application.
<User>
Hello there
<Chatbot Reply>
Hi, how can I help you?
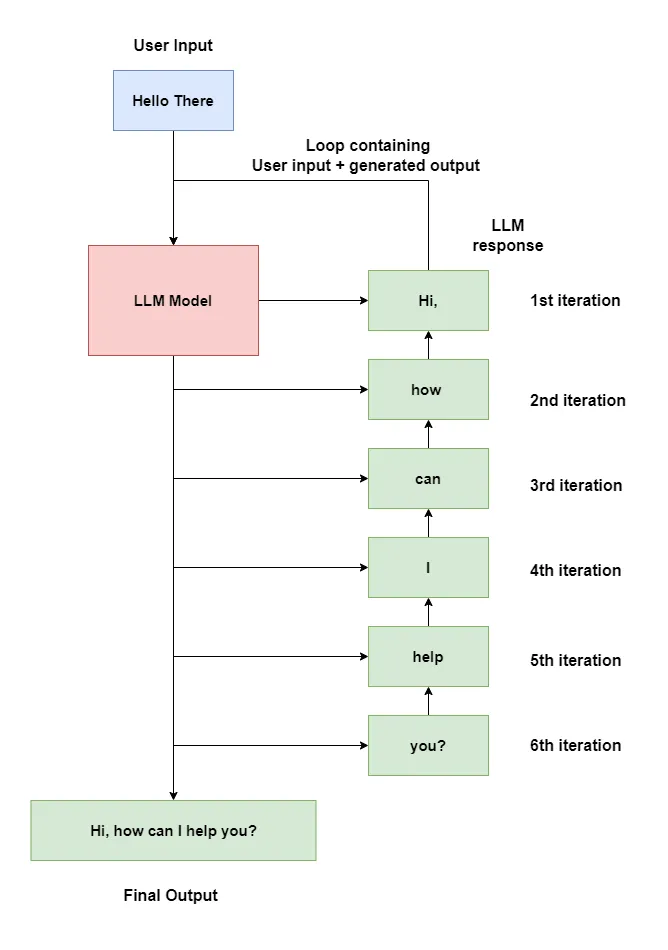
When a user asks something, the llm takes the user’s input and using its pre-trained knowledge tries to predict the next word (token to be more precise) that should follow the input sentence.
As LLMs are stateless, i.e. they don’t maintain any memory or state, their results aren’t affected by previous interactions. So for generating the next token, we give the model a combination of user input and the previously generated output as the new input again and again until it stops or reaches the end of the sentence.
The time it takes the model to generate an answer increases based on the output. In this case, the model loops roughly 6 times to generate the below output.
"Hello there" --> Hi,
"Hello there Hi," --> how
"Hello there Hi, how" --> can
"Hello there Hi, how can" --> I
"Hello there Hi, how can I" --> help
"Hello there Hi, how can I help" --> you?
"Hello there Hi, how can I help you?" --> |End of sentence|
So, what’s the reason behind the popularity of LLMs?
LLMs are incredibly versatile as they can perform a wide range of tasks including:
- Language Translation
- Content generation
- Chatbots
- Question answering with domain-specific knowledge
Their capability to understand context, tone, and intent in natural language makes them valuable for various real-life scenarios. Unlike previous approaches where each model is built for a specialized task from scratch with custom datasets, a single LLM can perform multiple similar tasks with just a little prompt engineering. This may still have some limitations as the responses may be generic.
But if we need an LLM to excel in a very specific task where prompt engineering isn’t enough, this is where fine-tuning comes in. Fine-tuning is a much simpler process compared to creating new models from scratch.
Applications like GitHub Copilot and ChatGPT use LLM models as a base. They are later fine-tuned for a specific task to deliver specialized responses in tasks like code generation and chat assistance.
Risks and Limitations of LLMs
LLMs are versatile but they aren’t an end-all solution to all problems. Simply using existing API services like OpenAI’s API to power a chatbot may work in some scenarios, but with some prompt engineering and proper architecture, we can dramatically improve our implementation without having to spend too many resources.
LLMs also aren’t always up to date. When asked questions beyond their established knowledge base, they may produce inaccurate or misleading answers, commonly called ‘Hallucination’.
They have a one-sided worldview based on their training dataset and may reflect the biases present in those datasets. Their replies only mimic the data and its structure they were trained on, so things intuitive or obvious to humans are not captured by LLMs.
Although LLMs lack domain-specific knowledge, providing enough context from external data sources can help improve responses to domain-specific questions and reduce hallucinations. This technique of using external data to provide relevant information to LLMs is known as Retrieval-Augmented Generation (RAG).
While LLMs are useful in many ways, they are by no means completely secure. Prompt injections, universal jailbreak prompts, and cryptic images are just a few examples attackers could use to leverage the vulnerabilities of LLMs.
Conclusion
Sure LLMs have opened up new ways of designing our software architectures; however, they have also introduced new vulnerabilities and exploits that could spiral out of control if not managed properly.
Not to mention their capabilities in generating content and mimicking human language raise concerns about misinformation, bias amplification, and privacy infringement. Balancing this technology safety and securely requires transparency and proper regulations to ensure responsible usage.