
Understanding Embeddings
Introduction to embeddings and their uses
 Yash Worlikar Mon Jan 08 2024 4 min read
Yash Worlikar Mon Jan 08 2024 4 min read Introduction
Ever wondered how Large language models work? It almost looks like they understand what they are talking about and can even hold up a proper conversation.
However, the reality is quite different. LLMs are incapable of truly understanding language like we do. Rather they learn the patterns present in natural language during their training and generate responses based on it.
Think of them as akin to parrots, mimicking what they see without understanding what they are saying.
These machine-learning models work with numbers to generate responses. So to use these models, we convert the words or entities into embeddings while retaining the meaning and context behind them.
Embeddings are essentially numerical representations of words. These vectors capture the important semantic features of the entities, making it possible for machine learning models to understand and work with.

Embeddings aren’t just limited to words though, they can also represent complex real-world objects or concepts such as images, audio, or even videos.
How embeddings work
Here’s a well-known example:
Man : King :: Women : ????
We can answer this question due to our reasoning and understanding of the language but the machine learning models can’t reason. They instead make predictions based on the input and generate the most likely output.
Let’s use a 2D graph to show how this works
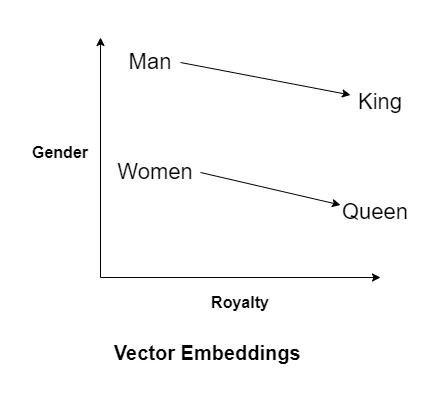
Here each word is mapped on a 2D graph based on its attributes. The relative positions of “Man” and “King” are similar to “Women” and “Queen” due to their features.
So using mathematical calculations the model can accurately predict the next word
King - Man + Woman = Queen
Words that are related to each other or have a similar context often appear in the same sentences and have similar structures. For example “apple” and “oranges” are more closer to each other compared to “apple” and “car”.
Traditional embedding techniques are used to generate embedding based on just words. But this doesn’t work well as words are dependent on context and can have vastly different meanings and forms. This was later improved by developing contextual embedding methods where the context is also considered.
So when we try to represent a word or sentence in numbers, the vectors will have similar values and thus will be closer to one another. These vectors can capture not just the word itself, but also its meaning, context, and even grammatical properties. It’s like a translator, turning language into a form the models can understand.
Instead of being just 2 dimensional, the entities are usually repsented using higher dimensions like 768 or 1536. This allows us to find patterns and capture data that may not be apparent or obvious to us.
Applications
Some of the common use cases of embeddings include:
- Retrieval systems: Embeddings help retrieval systems by representing the query as vectors and returning relevant results using similarity measures like cosine similarity or dot product.
- Search engines: Search engines like Google or Bing use embeddings to capture the semantic meaning and relevance of the query and the documents, and rank them accordingly.
- Recommendation systems: Recommendation systems can’t be defined effectively using traditional approaches. Embeddings can be used to define abstract thing things like user preferences and behavior.
Limitations
While embeddings can generate a good numerical representation of the words, it can be difficult to convert rare or new words not present in the training dataset leading to inaccurate results.
Embeddings trained on certain datasets might capture biases present in the data, leading to biased representations in downstream applications.
The quality of the embedding also depended on the size of the input data. Using smaller text chunks to create a single embedding may cause it to lose its context while using larger text chunks may result in a more generic representation making it harder for retrieval tasks.
Conclusion
Embeddings turn tricky language details into numbers, helping machines read, interpret, and create language-related information. They’re super useful in search engines, recommendations, and retrieval.
But, they do have some problems. So one must use them effectively and carefully to get the most out of them.
Still, they are the foundation of how computers handle natural language, sparking new ideas and changing how machines work with words. Making them better means constantly improving how we gather data and build these models.